问题
之前看过一篇文章,这里,其中讲述了blkio的测试结果。我自己也做了一些测试,发现对于buffer IO,bkio的throttle功能“似乎”也会发生作用,当时没有深入研究,直到最近,一个现网的IO问题促使我又仔细的研究了一下。
# cat blkio.throttle.write_bps_device
8:0 20971520
253:9 20971520
#dd if=/dev/zero of=f3.data bs=1M count=10240
其中,“8:0”为/dev/sda,“253:9”为容器rootfs对应的DM volume。
-
DM volume:
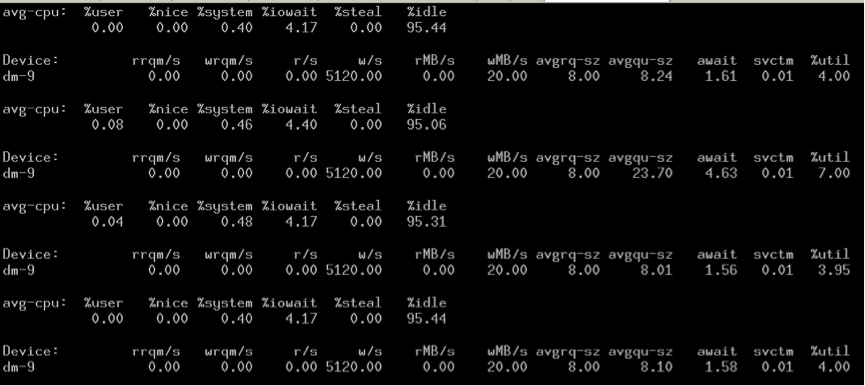
-
/dev/sda
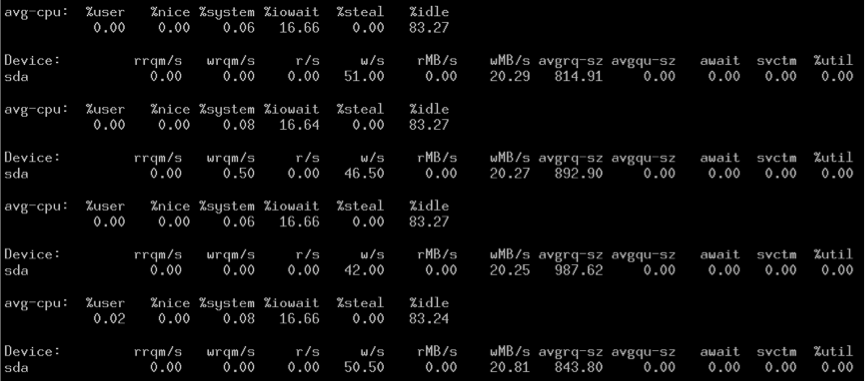
可以看到,两者“似乎”都限制在了20M/s。
直到前些天看到:
Currently only sync IO queues are support. All the buffered writes are still system wide and not per group. Hence we will not see service differentiation between buffered writes between groups.
了解到,目前内核blkio只支持sync IO/direct IO,对于buffer IO,无法进行IO throttle。 参考这里。
** 为什么这里的描述与实际测试的结果不太一致呢? **
Buffer IO
Buffer IO的基本过程如下:
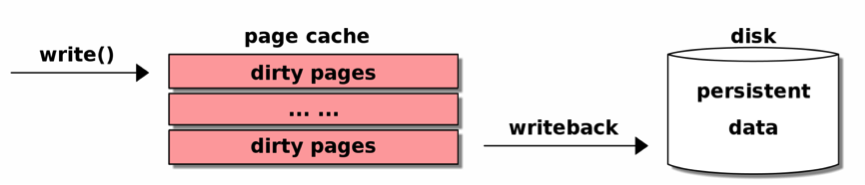
内核先将数据拷贝到page cache,然后再由后台内核线程定期刷到磁盘。
其中在内核的详细实现如下(基于CentOS6.5的内核):
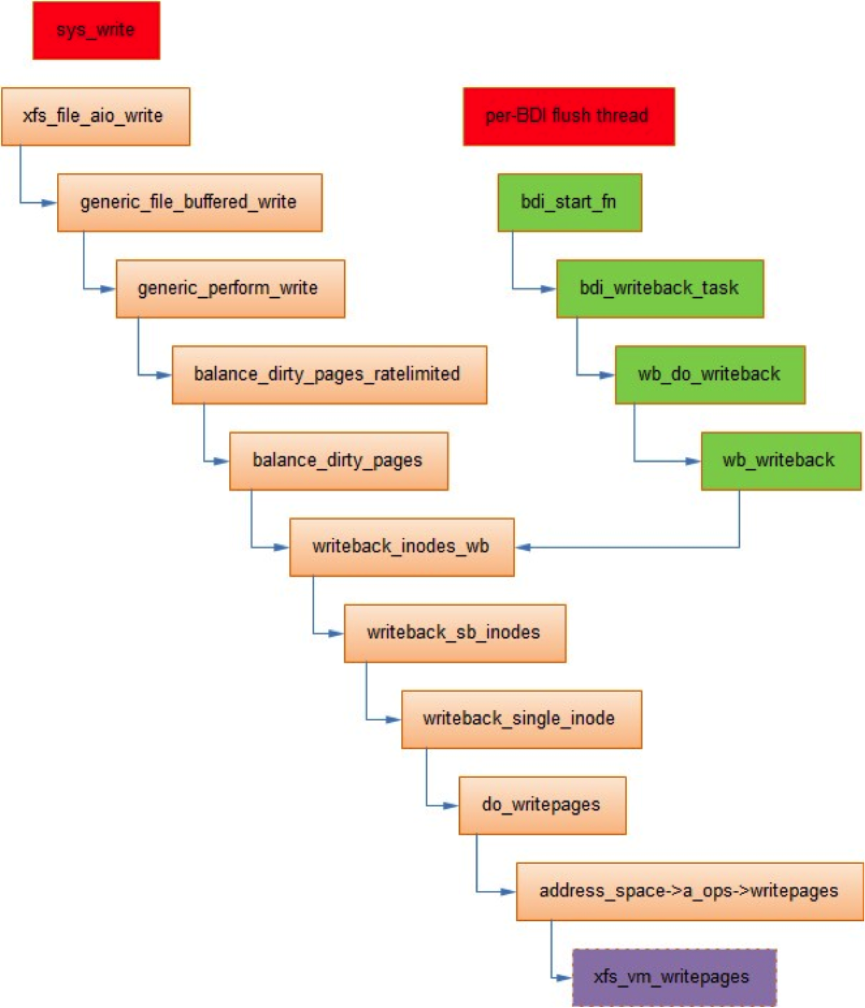
在3.2之前的内核,在sys_write的路径上,balance_dirty_pages会检查系统中的脏页,如果脏页比例超过vm.dirty_ratio,会在应用进程上下文中触发同步刷盘操作,CentOS6.5的情况稍微更复杂一点。
这种方式有很多问题,其中最大的问题就是这可能会产生过多的离散IO(seeky I/O),这会降低系统的整体吞吐率。所以,3.2引入了I/O-less dirty throttling。基本的思想就是所有的刷盘操作在后台进行,如果进程的产生脏页的速度超过限制,就让进程主动sleep。 该patch由Intel的FengguangWu实现,其中的算法很复杂,开始的时候,很多内核开发者并不接受,因为看不懂,说实话我也没怎么看懂。
分析
回到我们的问题,简单trace了一下kernel,发现blkio throttle生效的时候,bio都是由内核线程kthrotld下发的:
# ./tpoint -s block:block_bio_queue
kthrotld/8-323 [008] 10929769.540355: block_bio_queue: 8,0 WS 1260299776 + 1024 [kthrotld/8]
kthrotld/8-323 [008] 10929769.540355: <stack trace>
=> generic_make_request
=> blk_throtl_work
=> worker_thread
=> kthread
=> child_rip
kthrotld/8-323 [008] 10929769.640390: block_bio_queue: 8,0 WS 1260300800 + 1024 [kthrotld/8]
kthrotld/8-323 [008] 10929769.640391: <stack trace>
=> generic_make_request
=> blk_throtl_work
=> worker_thread
=> kthread
=> child_rip
这让我大吃一惊,按理来说,bio应该由flush线程下发才对啊。
kthrotld
每个块设备的request_queue都有一个内核线程kthrotld,当上层提交bio的速度超过throtl_grp中的限制时,就会将bio加入到对应控制组的throtl_grp->bio_lists队列,并将throtl_grp加入到throtl_data->tg_service_tree中。
内核线程kthrotld从throtl_data->tg_service_tree取出throtl_grp,然后再取出其中的bio,下发调度层。整体流程如下:
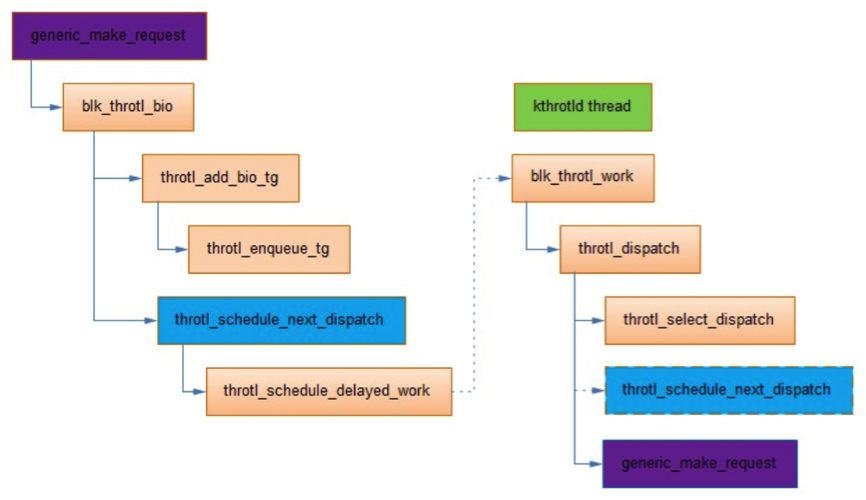
结论
到这里,基本上可以断定进程触发了同步刷盘,使得blkio.throttle.write_bps_device 起了作用,这也解释了为什么bio都由kthrotld内核线程下发。
static inline void __generic_make_request(struct bio *bio)
{
...
do {
...
if (blk_throtl_bio(q, bio)) ///io limit check
break; /* throttled, will be resubmitted later */
trace_block_bio_queue(q, bio);
ret = q->make_request_fn(q, bio);///blk_queue_bio
} while (ret);
...
如果sys_write触发的同步bio被throttled,那么blk_throtl_bio应该返回true。
#./kprobe -s 'r:blk_throtl_bio $retval'
<...>-38579 [008] 11173643.427425: blk_throtl_bio: (generic_make_request+0x1f3/0x5a0 <- blk_throtl_bio) arg1=1
<...>-38579 [008] 11173643.427425: <stack trace>
=> submit_bio
=> xfs_submit_ioend_bio
=> xfs_submit_ioend
=> xfs_vm_writepage
=> __writepage
=> write_cache_pages
=> generic_writepages
=> xfs_vm_writepages
<...>-38579 [008] 11173643.427432: blk_throtl_bio: (generic_make_request+0x1f3/0x5a0 <- blk_throtl_bio) arg1=1
<...>-38579 [008] 11173643.427432: <stack trace>
=> submit_bio
=> xfs_submit_ioend_bio
=> xfs_submit_ioend
=> xfs_vm_writepage
=> __writepage
=> write_cache_pages
=> generic_writepages
=> xfs_vm_writepages
从trace的结果来看,的确是这样。
#总结
3.2之后的内核,进程再也不会触发同步刷盘的逻辑,所以这里的现象也不会再出现。另外,很早之前,就有人尝试实现buffer IO throttle,参考blk-throttle: writeback and swap IO control,但一直没有进入主线。
直到最近,Cgroup的maintainer Tejun Heo又提出实现buffered IO的throttle,参考writeback: cgroup writeback support。这个patch涉及的面比较广,涉及到memcg、blkcg还需要fs、cfq-iosched等子系统的联动,进入主线需要一些时间。