问题描述
业务同事在TDocker做压测的时候,因为负载太大,将容器内存用完,导致容器卡死,系统CPU 100%。
原因分析
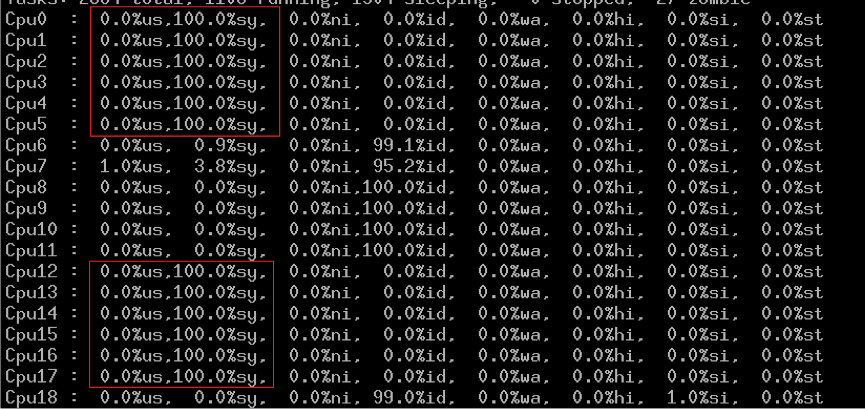
先看卡死的容器在做什么,为什么系统CPU会达到100%呢?
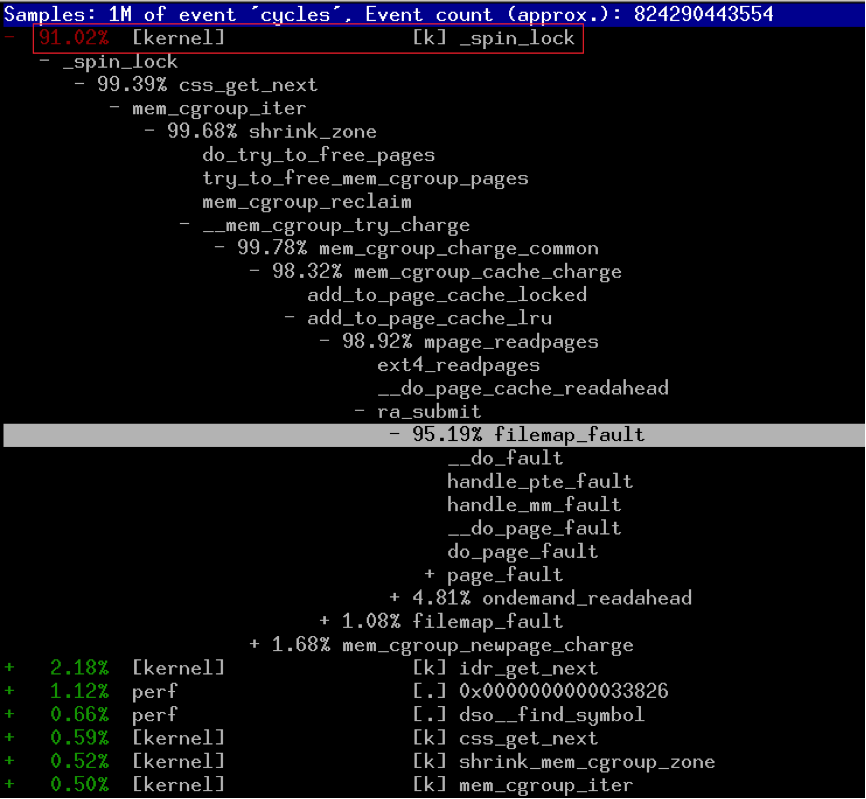
从这里可以看到,是由于内核的自旋锁引起的:
struct cgroup_subsys_state *
css_get_next(struct cgroup_subsys *ss, int id,
struct cgroup_subsys_state *root, int *foundid)
{
...
while (1) {
/*
* scan next entry from bitmap(tree), tmpid is updated after
* idr_get_next().
*/
spin_lock(&ss->id_lock);
tmp = idr_get_next(&ss->idr, &tmpid);
spin_unlock(&ss->id_lock);
从cgroup的代码来看,这里的确有个自旋锁。
另外,从内核函数的调用路径来看,是由于cgroup内存不足引起的。 按理说,如果业务程序使用的内存超过cgroup的limit,cgroup会KILL掉业务进程的,难道cgroup的OOM kill没有生效?
从host看了一下,容器内部跑了1000多个进程,平均每个进程占用大约几M~20M的物理内存,难道是因为进程数量cgroup来不及OOM kill引起的。
[ pid ] uid tgid total_vm rss cpu oom_adj oom_score_adj name
[15947] 0 15947 29022 26 5 0 0 init
[16944] 0 16944 1016 15 5 0 0 mingetty
[19813] 0 19813 42155 101 0 0 0 agent
[19818] 0 19818 2117 28 2 0 0 agentPlugInD
…
[40391] 30000 40391 174693 2157 2 0 0 node
[40392] 30000 40392 174693 2033 1 0 0 node
[40393] 30000 40393 174693 1836 2 0 0 node
[40394] 30000 40394 174693 2030 0 0 0 node
[40395] 30000 40395 175717 3474 2 0 0 node
[40396] 30000 40396 174693 1894 4 0 0 node
[40437] 30000 40437 174693 2051 4 0 0 node
Memory cgroup out of memory: Kill process 15947 (init) score 1 or sacrifice child
Killed process 16944, UID 0, (mingetty) total-vm:4064kB, anon-rss:4kB, file-rss:56kB
node invoked oom-killer: gfp_mask=0xd0, order=0, oom_adj=0, oom_score_adj=0
node cpuset=d96a8ea034f0610b31f1f669b7083d73f7caf7be92dae187ceb86416d05e1955 mems_allowed=0-1
从内核的oom log来看,内核似乎并没有KILL用内存相对更多的业务进程(node),而KILL掉了另外一个系统进程mingtty。
测试
为了重现这个情况,写了个简单的测试程序:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#define MAX_PROCESS 1280
#define BUF_SIZE 8388608
int main(int argc, char* argv[]){
pid_t pid;
int i;
for( i = 0; i < MAX_PROCESS; i++){
pid = fork();
if(pid == 0){
char *p = (char*)malloc(BUF_SIZE);
memset(p, 0, BUF_SIZE);
sleep(60);
exit(0);
}else if(pid < 0){
perror("fork");
}else{
}
if(i % 100 == 0)
fprintf(stdout, "created %d process\n", i);
}
fprintf(stdout, "created %d process\n", i);
while( -1 != wait(NULL)){
}
sleep(10);
fprintf(stdout, "all process exit\n");
return 0;
}
容器分配8G的内存(另外+2G swap),创建1280个进程,每个进程使用8M的内存,共10G内存,用完容器的所有内存。马上重现容器卡死,而且内核OOM日志看到不测试进程被KILL的。
内核分析
CentOS6.5内核计算进程oom score的代码: oom_badness:
unsigned int oom_badness(struct task_struct *p, struct mem_cgroup *mem,
const nodemask_t *nodemask, unsigned long totalpages)
{
...
/*
* The memory controller may have a limit of 0 bytes, so avoid a divide
* by zero, if necessary.
*/
if (!totalpages)
totalpages = 1;
/*
* The baseline for the badness score is the proportion of RAM that each
* task's rss, pagetable and swap space use.
*/
points = get_mm_rss(p->mm) + p->mm->nr_ptes;
points += get_mm_counter(p->mm, swap_usage);
points *= 1000;
points /= totalpages;
task_unlock(p);
/*
* Root processes get 3% bonus, just like the __vm_enough_memory()
* implementation used by LSMs.
*/
if (has_capability_noaudit(p, CAP_SYS_ADMIN))
points -= 30;
/*
* /proc/pid/oom_score_adj ranges from -1000 to +1000 such that it may
* either completely disable oom killing or always prefer a certain
* task.
*/
points += p->signal->oom_score_adj;
/*
* Never return 0 for an eligible task that may be killed since it's
* possible that no single user task uses more than 0.1% of memory and
* no single admin tasks uses more than 3.0%.
*/
if (points <= 0)
return 1;
return (points < 1000) ? points : 1000;
}
进程分数=(进程使用的内存
业务进程数量越多,每个进程分配到的内存越少,那么进程的分数越低,就越不可能被kill。这里会导致一个临界值,
- 对于root进程,
(进程使用的内存*1000)/group总的内存>= 30时,即业务进程使用3%以上内存,
业务进程才有可能被选中。
- 对于非root进程,
(进程使用的内存*1000)/group总的内存>= 1时,即业务进程使用1‰以上内存,
业务进程才有可能被选中。 当业务进程数超过1000,每个进程分到的进程必然小于1‰,所以内核OOM日志没有出业务进程。
再做一些测试,容器分配8G内存(另外2G swap),
*(1)以非root运行1280个进程,每个进程8M,还是会出现卡死。 < 1‰
*(2)但如果非root运行80个进程,每个进程128M内存,不会出现卡死。 > 1‰
*(3)但如果以root运行80个进程,每个进程128M内存,还是会出现卡死。< 3%
这里的问题在于根据内核计算进程oom的分数,能否选中业务进程,如果不能选中业务进程,就会出现卡死,如果选中了业务进程,就不会出现。
解决方法
较新的内核,比如3.10.x,已经去掉了这里的spin lock,同时调整了oom score的算法,不会导致这个问题。后续将TDocker升级到3.10.x的内核。