Cgroup V2
Cgroup在内核的实现一直比较混乱,受到很多人的诟病,甚至不乏有人想将其从内核移出。其中,最主要原因在于,cgroup为了提供灵活性,允许进程可以属于多个hierarchy的不同group。但实际上,多个hierarchy并没有太大的用处,因为控制器(controller)只能属于一个hierarchy。所以,在实际使用中,通常是每个hierarchy一个controller。
这种多hierarchy除了增加代码的复杂度和理解困难外,并没有太大用处。一方面,跟踪进程所有controller变得复杂;另外,各个controller之间也很难协同工作(因为controller可能属于不同的hierarchy)(注:正是由于memcg与blkio没有协作,导致buffer io的throttle一直没有实现,不过已经在4.2实现)。所以从3.16开始,内核开始转向单一层次(unified hierarchy)。
V2 feature
V2相对于V1,规则发生了一些变化。每个控制组(control group)都有一个cgroup.controllers文件,列出子group可以开启的controller。另外,还有一个 cgroup.subtree_control文件,用于控制开启/关闭子group的controller。
另外,控制组与controller之间的关系,也发生了一些变化。考虑如下控制组:
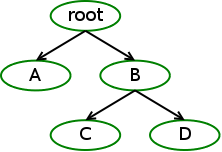
(1)控制组对子控制组要么都开启,要么都不开启某个controller。比如,如果对B的cgroup.subtree_control写入memory controller,那么就会同时应用到C和D。
(2)只有父控制组开启了controller,子控制组才能开启某个controller。比如,只有B开启了memory,C才能开启memory。但关闭不受这个限制,B开启了memory,C可以关闭。 但是,子控制组并不会自动开启父控制组的所有controller,需要手动去开启。
(3)只有不包含task的控制组才能通过cgroup.subtree_control开启controller,根控制组除外。也就是说,只有叶子控制组才能对进程进行资源控制。例如,B不能包含进程信息。 这样做主要是为了防止父控制组中的进程与子控制组的进程发生资源竞争,而且关系不明确。
通过上面这些规则,使得整个cgroup系统成为一棵树(而不是之前的多个树),而且所有进程的资源控制都在叶子控制组进行。更加简单,也更好理解。总而言之,cgroup在向更简单、更实用的方向发展。
Cgroup writeback support
blkio cgroup一直有一个很大的问题,只能对direct IO进行throttle,对于buffer IO,由于块层和调度层都拿不到真正IO发起的进程信息(所有bio都由后台flush线程发给块层),所以,没有办法进行IO throttle,可以参考这里。
内核在4.2合入了Tejun Heo的writeback support patch。主要通过memcg和blkcg协作完成了buffer IO的throttle,具体实现后面再讨论。另外,值得一提是,还需要文件系统的支持。目前ext2/ext4都支持。
下面简单测试一下。
practice
基于内核4.3.3。
** 开启memcg和blkcg **
# mount -t cgroup -o __DEVEL__sane_behavior cgroup /cgroup/unified/
# ls /cgroup/unified/
cgroup.controllers cgroup.procs cgroup.subtree_control io.stat memory.current pids.current
# cat /cgroup/unified/cgroup.controllers
io memory pids
# echo "+memory +io" > /cgroup/unified/cgroup.subtree_control
# cat /cgroup/unified/cgroup.subtree_control
io memory
** 创建控制组 **
# mkdir /cgroup/unified/docker
# mkdir /cgroup/unified/docker/vm1
# cat cgroup/unified/docker/cgroup.subtree_control
# echo "+memory +io" > /cgroup/unified/docker/cgroup.subtree_control
# ls /cgroup/unified/docker/vm1/
cgroup.controllers cgroup.procs io.max io.weight memory.events memory.low
cgroup.populated cgroup.subtree_control io.stat memory.current memory.high memory.max
** 测试1 **
将IO限制为1M/s
# echo "8:0 wbps=1048576" > /cgroup/unified/docker/vm1/io.max
# echo $$
5375
# cat /cgroup/unified/docker/vm1/cgroup.procs
# echo $$ > /cgroup/unified/docker/vm1/cgroup.procs
# cat /cgroup/unified/docker/vm1/cgroup.procs
5375
14195
结果如下:
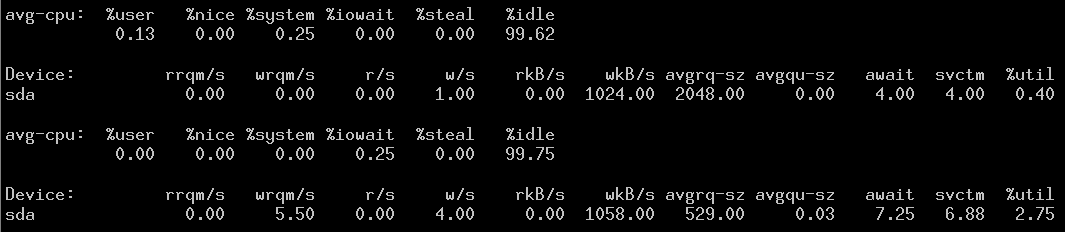
# dd if=/dev/zero of=/data/f1.data bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 1.28482 s, 836 MB/s
** 测试2 **
将IO限制为10M/s
# echo "8:0 wbps=10485760" > /cgroup/unified/docker/vm1/io.max
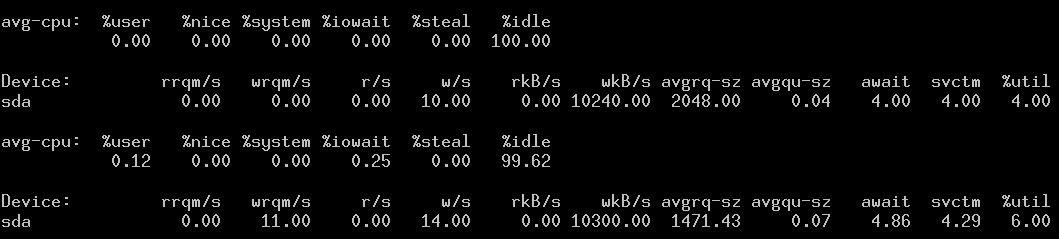
# dd if=/dev/zero of=/data/f1.data bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 1.30408 s, 823 MB/s
值得注意的是,dd很快就执行完了,但从IO来看,是符合预期的。这是由于dd很快就将数据写到了page cache,但writeback内核线程在进行下发给块层时,受到blkcg的限制。
下面对内存做一下限制。我们将内存限制为100M。
# cat /cgroup/unified/docker/vm1/memory.current
1074515968
# echo 104857600 > /cgroup/unified/docker/vm1/memory.max
# cat /cgroup/unified/docker/vm1/memory.current
104845312
# dd if=/dev/zero of=/data/f1.data bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 119.112 s, 9.0 MB/s
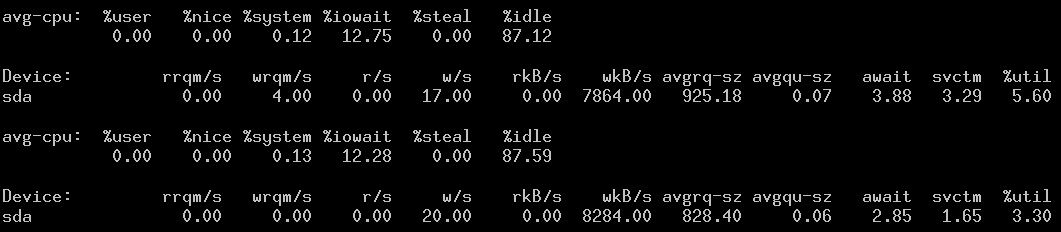
可以看到dd运行了119s才完成。
看一下内存的变化:
# cat /cgroup/unified/docker/vm1/memory.current
103657472
总结
从测试情况来看,Tejun Heo的patch达到了buffer IO throttle的目的。但该patch本身改动比较大,包含40多个子patch,而且由于整个cgroup的架构已经转向unified hierary,想把该特性移植到低版本的内核,难度会比较大。另外,从提供给应用层的接口来看,也发生了变化,如果docker想使用,底层代码还需要做一些调整。 最后,也是最重要的一点,整个cgroup这些新的特性还处于开发中,希望在下一个longterm版本中能够稳定下来。