MPI中的Collective操作实现MPI多个进程间的通信。
MPI_Barrier
MPI_Barrier可以实现MPI进程间的同步,只有所有进程都到达该同步点(synchronization point),才能继续向下执行。
MPI_Barrier(MPI_Comm communicator)
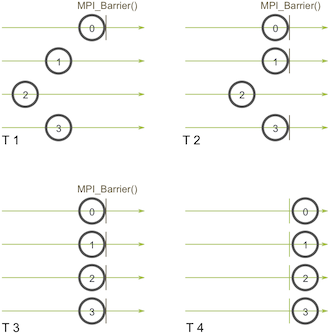
对于上图,进程P0在T1时刻到达barrier点,就会陷入等待,不能往下运行,因为其它进程还没有执行到这里。当T4时刻,所有进程都到达该barrier点时,所有进程才能继续往下运行。
MPI_Bcast
MPI_Bcast实现广播,即一个进程将相同的数据发送给其它进程:
MPI_Bcast(
void* data,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm communicator)
发送进程和接收进程都调用MPI_Bcast,root指定发送进程。对于发送者,data指向发送数据;对于接收者,接收到的数据保存到data指定的存储空间。
- 如何实现广播呢?
最简单的方式,是发送进程,通过循环遍历,依次向其它进程发送(MPI_Send)数据,但这种方式的时间复杂度为O(N)。下面是一种更高效的方式的实现:
stage1: 0 -> 1
stage2: 0 -> 2, 1 -> 3
stage3: 0 -> 4, 1 -> 5, 2 -> 6, 3 -> 7
在第1个阶段,进程0发送给进程1; 在第2个阶段,进程0发送给进程2,同时,进程1发送给进程3;这样,通过3轮迭代,就完成了数据广播。显然,这种树形算法的复杂度为O(logN)。
MPI_Scatter
MPI_Scatter与MPI_Bcast类型,也是root进程发送数据到其它所有进程,但不同的是,MPI_Scatter将发送缓冲区的数据分成大小相同的chunk,对不同的进程,发送不同的chunk。

MPI_Scatter(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
send_data是在root进程上的一个数据数组,send_count和send_datatype分别描述了发送给每个进程的数据数量和数据类型。recv_data为接收进程的缓冲区,它能够存储recv_count个recv_datatype数据类型的元素。root指定发送进程。
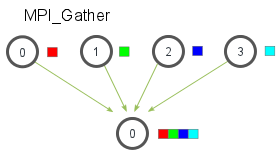
MPI_Gather
MPI_Gather是MPI_Scatter的反向操作,从多个进程汇总数据到一个进程。
MPI_Gather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
在MPI_Gather中,只有root进程需要一个有效的接收缓存。所有其他的调用进程可以传递NULL给recv_data。另外,值得注意的是,recv_count参数是从每个进程接收到的数据数量,而不是所有进程的数据总量之和。
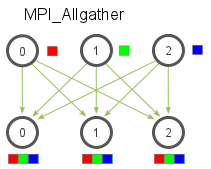
MPI_Allgather
MPI_Allgather是一种多对多的通信方式,每个进程都会从所有进程收集数据。一般来说,MPI_Allgather相当于一个MPI_Gather操作之后跟着一个MPI_Bcast操作。
MPI_Allgather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
MPI_Comm communicator)
相对于MPI_Gather,没有root参数。
MPI_Reduce
与MPI_Gather类似,MPI_Reduce实现root进程从所有进程读取数据。但多了一个MPI_Op参数,用于指定对数据缓冲区send_data中每个数据元素进行的计算操作。
MPI_Reduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm communicator)
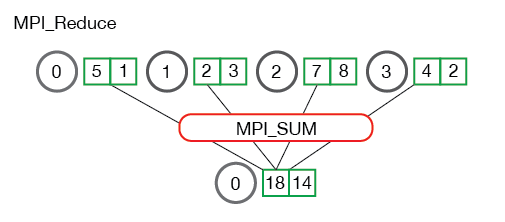
所有进程send_data中第i个数据元素做相应的计算,然后写到recv_data中第i个单元。
instead of summing all of the elements from all the arrays into one element, the ith element from each array are summed into the ith element in result array of process 0.
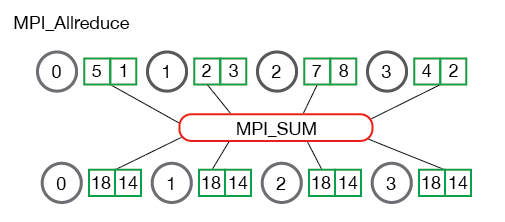
MPI_Allreduce
MPI_Allreduce对MPI_Reduce,相当于MPI_Allgather对MPI_Gather:
MPI_Allreduce(
void* send_data,
void* recv_data,
int count,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm communicator)
MPI_Allreduce不需要指定root进程,相当于MPI_Reduce操作之后,跟一个MPI_Bcast操作。
Ring Allreduce
MPI_AllReduce这个通信原语背后,MPI中实现了多种AllReduce算法,包括Butterfly,Ring AllReduce,Segmented Ring等。
Ring AllReduce主要针对数据块过大的情况,把每个节点的数据切分成N份(相当于scatter操作)。所以,ring allreduce分2个阶段操作:
- (1) scatter-reduce
通过(N-1)步,让每个节点都得到1/N的完整数据块。每一步的通信耗时是α+S/(NB),计算耗时是(S/N)*C。 这一阶段也可视为scatter-reduce。
- (2) all-gather
通过(N-1)步,让所有节点的每个1/N数据块都变得完整。每一步的通信耗时也是α+S/(NB),没有计算。这一阶段也可视为allgather。