体系结构
CPU与GPU
GPU与CPU设计处理的计算任务的目标是不一样的,导到两者的整体结构有很大的区别:
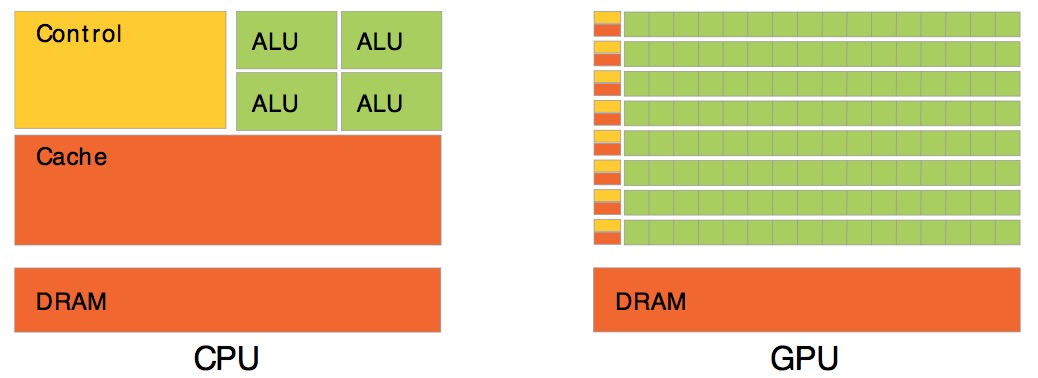
具体来说,CPU是一种低延迟的设计:
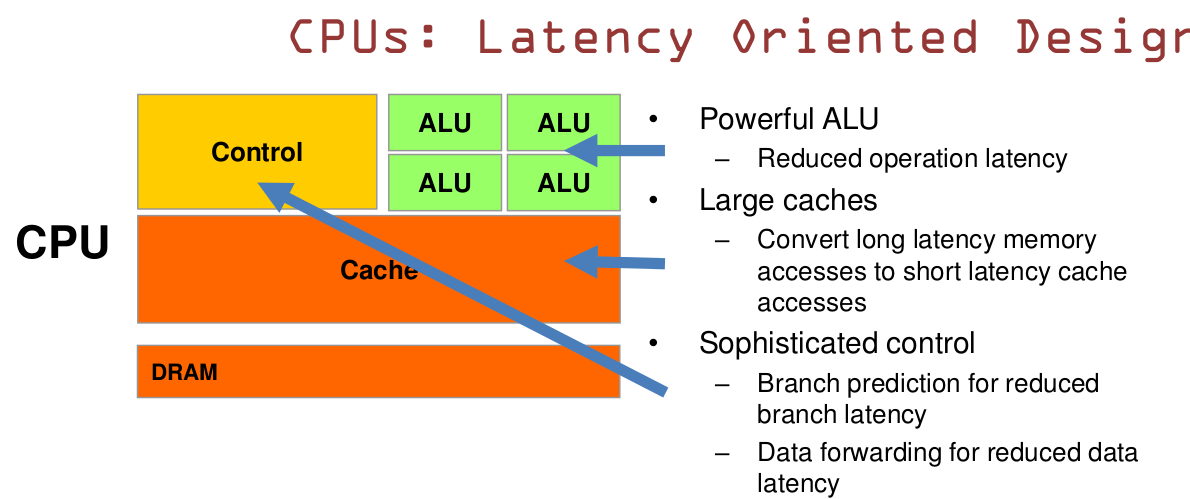
(1) CPU有强大的ALU,时钟频率很高; (2) CPU的容量较大的cache,一般包括L1、L2和L3三级高速缓存;L3可以达到8MB,这些cache占据相当一部分片上空间; (3) CPU有复杂的控制逻辑,例如:复杂的流水线(pipeline)、分支预测(branch prediction)、乱序执行(Out-of-order execution)等;
这些设计使得真正进行计算的ALU单元只占据很小一部分片上空间。
而GPU是一种高吞吐的设计,具体来说:
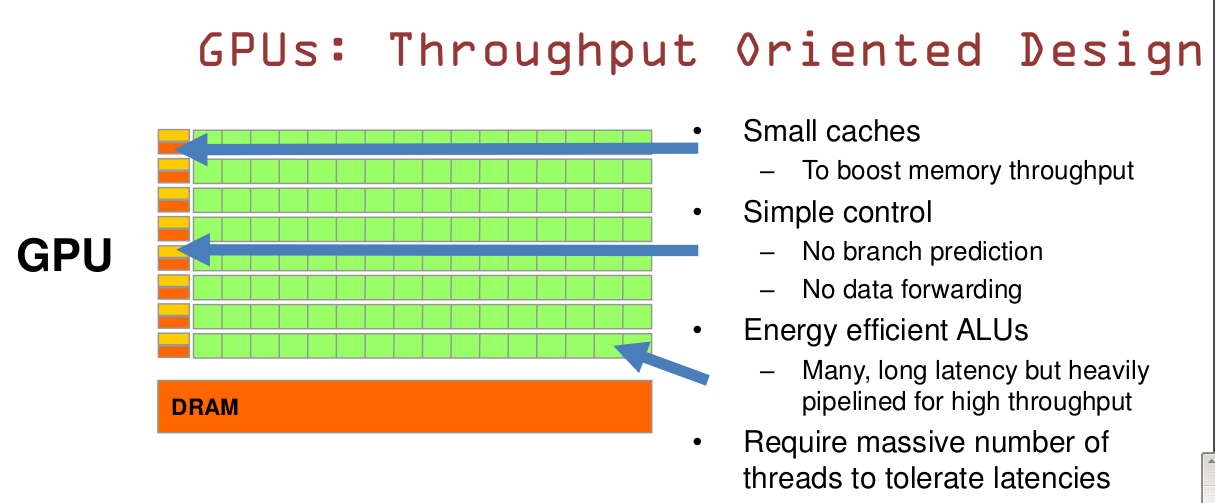
(1) GPU有大量的ALU; (2) cache很小;缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的; (2) 没有复杂的控制逻辑,没有分支预测等这些组件;
总的来说,CPU擅长处理逻辑复杂、串行的计算任务;而GPU擅长的是大规模的数据并行(data-parallel)的计算任务。
GPU体系结构
- GPU内部结构
一个“假想”的GPU Core结构如下:
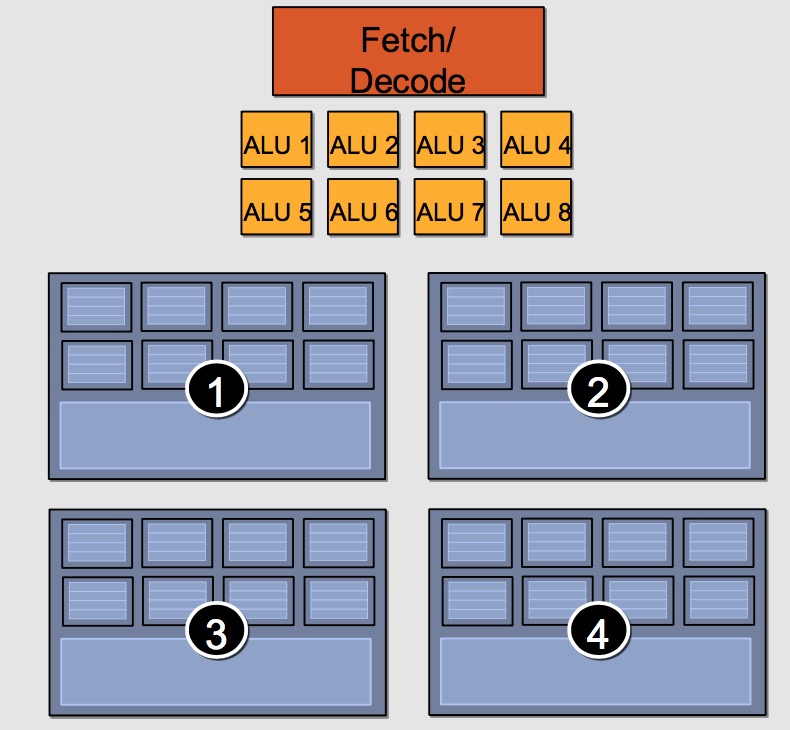
它包括8个ALU,4组执行环境(Execution context),每组有8个Ctx。这样,一个Core可以并发(concurrent but interleaved)执行4条指令流(instruction streams),32个并发程序片元(fragment)。
我们用16个上面的Core构成一个GPU,如下:
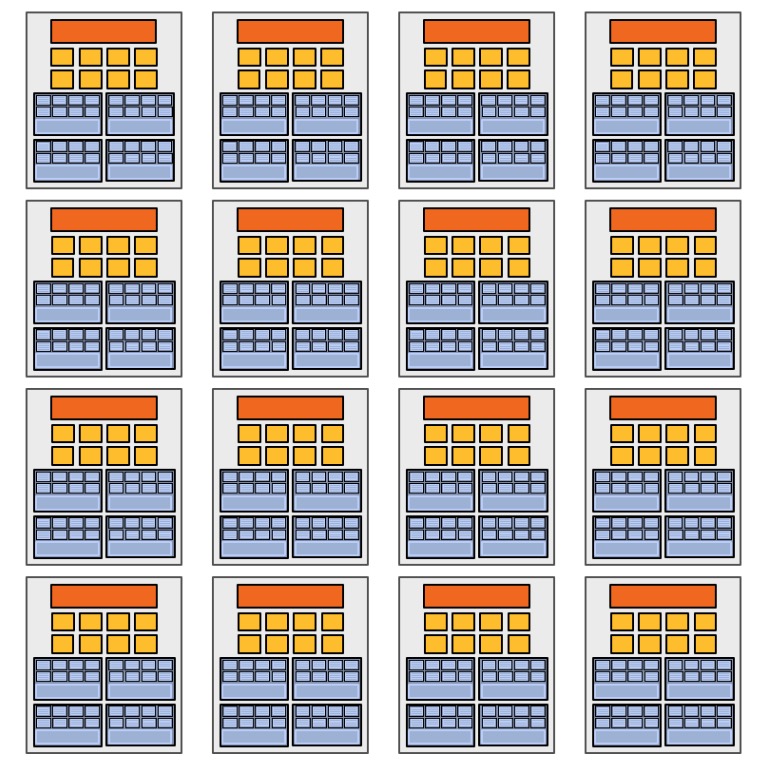
这样,一个GPU有16个Core、128个ALU,可以同时处理16条指令流、64条并发指令流、512(32*16)个并发程序片元。
- 示例
以NVIDIA GeForce GTX 580为例,每个GPU Core的内部如下:
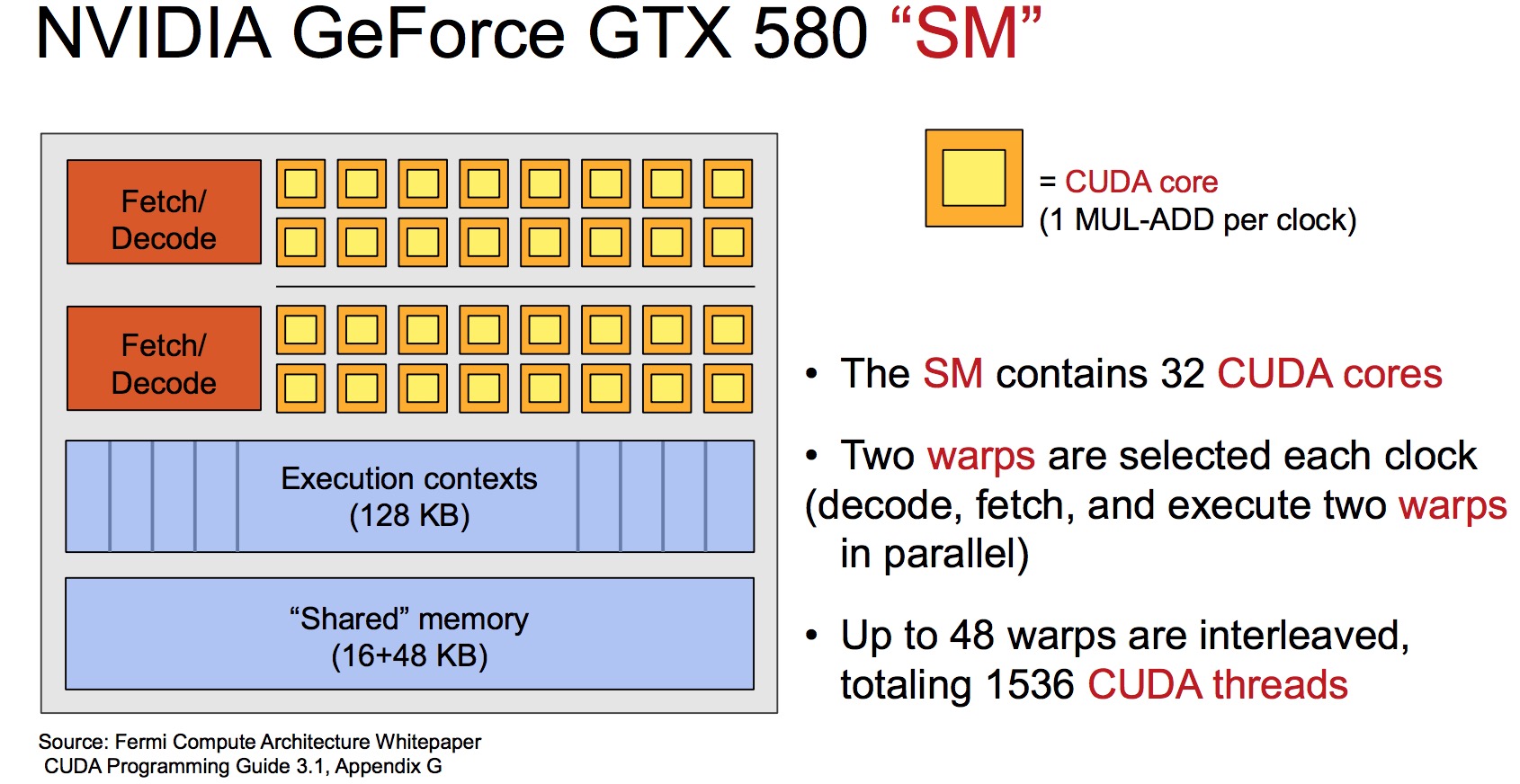
每个Core有64个CUDA core(也叫做Stream Processor, SP),每个CUDA core可以理解为一个复杂完整的ALU。这些CUDA core,分成2组,每组32个CUDA core,共享相同的取指/译码部件,这一组称为Stream Multiprocessor(SM) 。
每个Core可以并发执行1536个程序片元,即1536个CUDA threads。
一个GTX 580GPU包含16个Core,总共1024个CUDA core,可以并发执行24576(1536*16)个CUDA threads.

数据存储
CPU的典型存储结构如下:
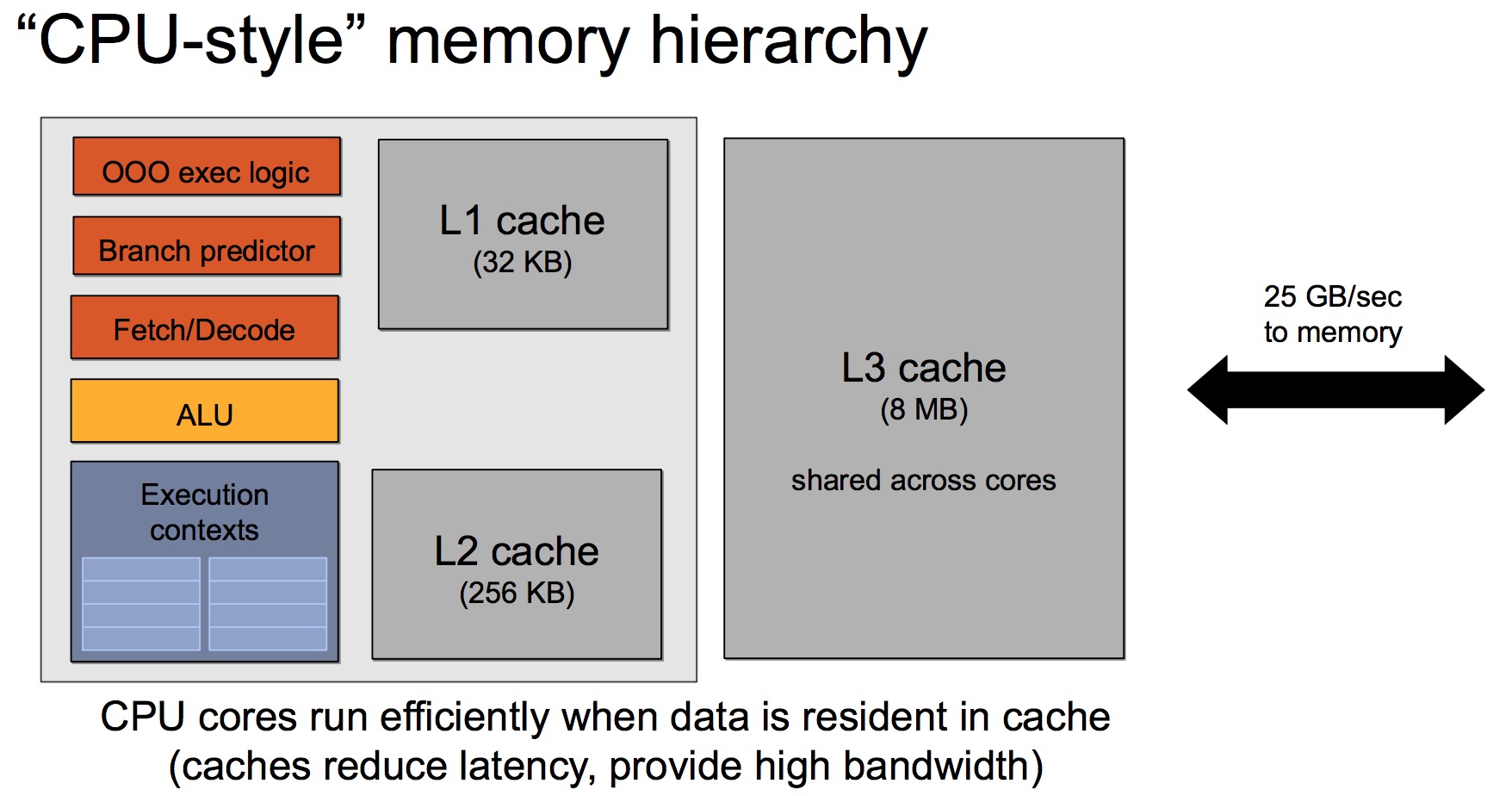
一般来说,CPU和内存之间的带宽只有数十GB/s。比如对于Intel Xeon E5-2699 v3,内存带宽达到68GB/s((2133 * 64 / 8)*4 MB/s):
| 内存规格 | |
|---|---|
| 最大内存大小(取决于内存类型) | 768 GB |
| 内存类型 | DDR4 1600/1866/2133 |
| 最大内存通道数 | 4 |
| 最大内存带宽 | 68 GB/s |
而GPU的存储结构一般如下:
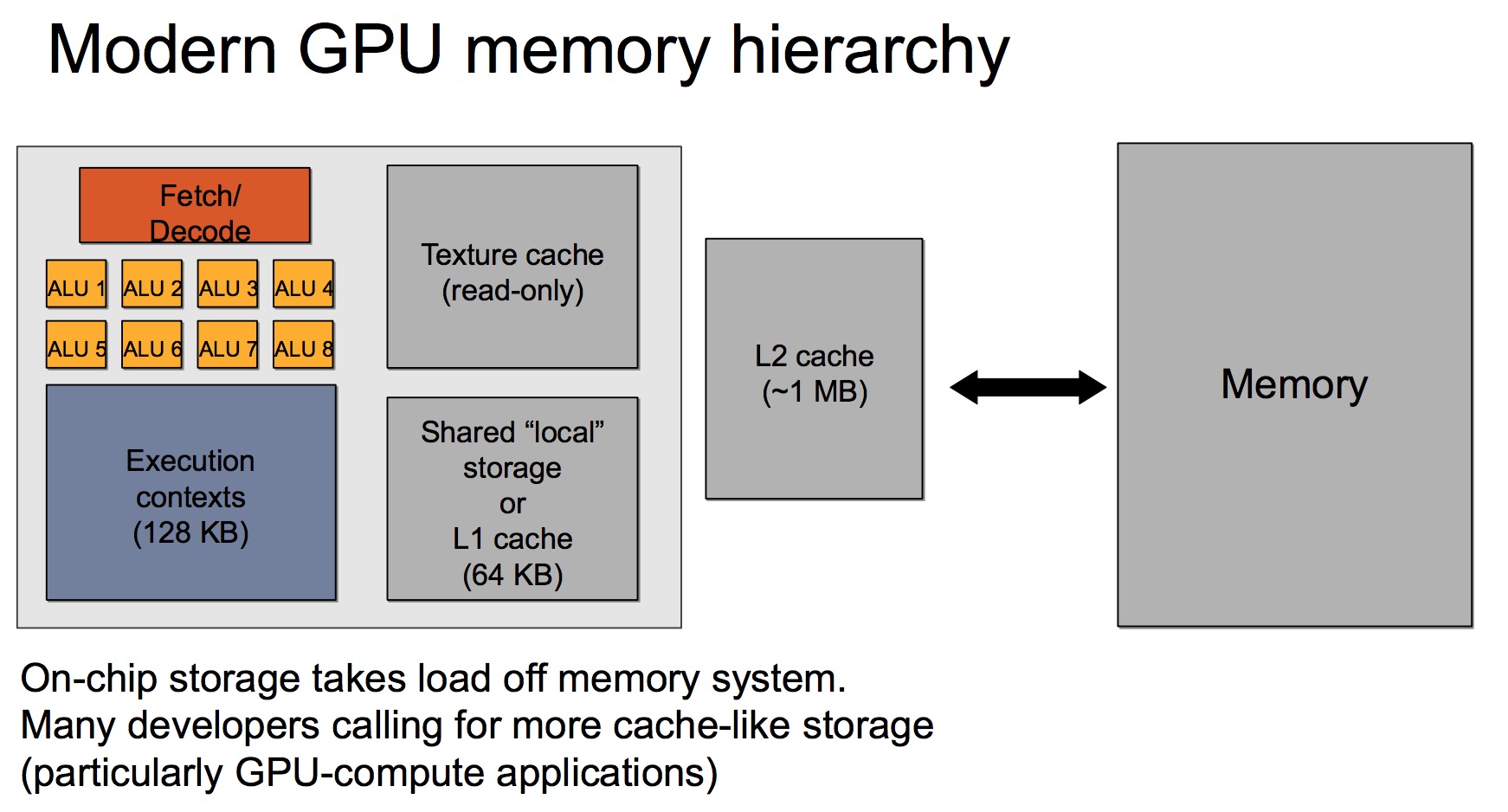
GPU的高速缓存较小,上图的Memory实际上是指GPU卡内部的显存。但是与显存之间的带宽可以达到数百GB/s,比如P40的显存带宽为346GB/s,远远大于CPU的内存带宽,但是,相对于GPU的计算能力,显存仍然是瓶颈所在。
CPU与GPU交互
在现代的异构计算系统中,GPU是以PCIe卡作为CPU的外部设备存在,两者之间通过PCIe总线通信:
---------- ------------
|___DRAM___| |___GDRAM____|
| |
---------- ------------
| CPU | | GPU |
|__________| |____________|
| |
--------- --------
|___IO____|---PCIe---|___IO___|
对于PCIe Gen3 x1理论带宽约为1000MB/s,所以对于Gen3 x32的最大带宽为~32GB/s,而受限于本身的实现机制,有效带宽往往只有理论值的2/3还低。所以,CPU与GPU之间的通信开销是比较大的。
CUDA编程模型
在对GPU的体系结构有了基本的了解之后,来看看CUDA的编程模型,这是进行CUDA编程的基础。
Kernel
一个CUDA程序的可以分为两个部分: 在CPU上运行的Host程序;在GPU上运行的Device程序。两者拥有各自的存储器。GPU上运行的函数又被叫做kernel函数,通过__global__关键字声名,例如:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
Host程序在调用Device程序时,可以通过<<<...>>>中的参数提定执行该kernel的CUDA threads的数量。每个Thread在执行Kernel函数时,会被分配一个thread ID,kernel函数可以通过内置变量threadIdx访问。
线程层次 (Thread Hierarchy)
CUDA中的线程组织为三个层次Grid、Block、Thread。threadIdx是一个3-component向量(vector),所以线程可以使用1维、2维、3维的线程索引(thread index)来标识。同时由多个线程组成的thread block也可以分别是1维、2维或者3维的。
For convenience, threadIdx is a 3-component vector, so that threads can be identified using a one-dimensional, two-dimensional, or three-dimensional thread index, forming a one-dimensional, two-dimensional, or three-dimensional block of threads, called a thread block.
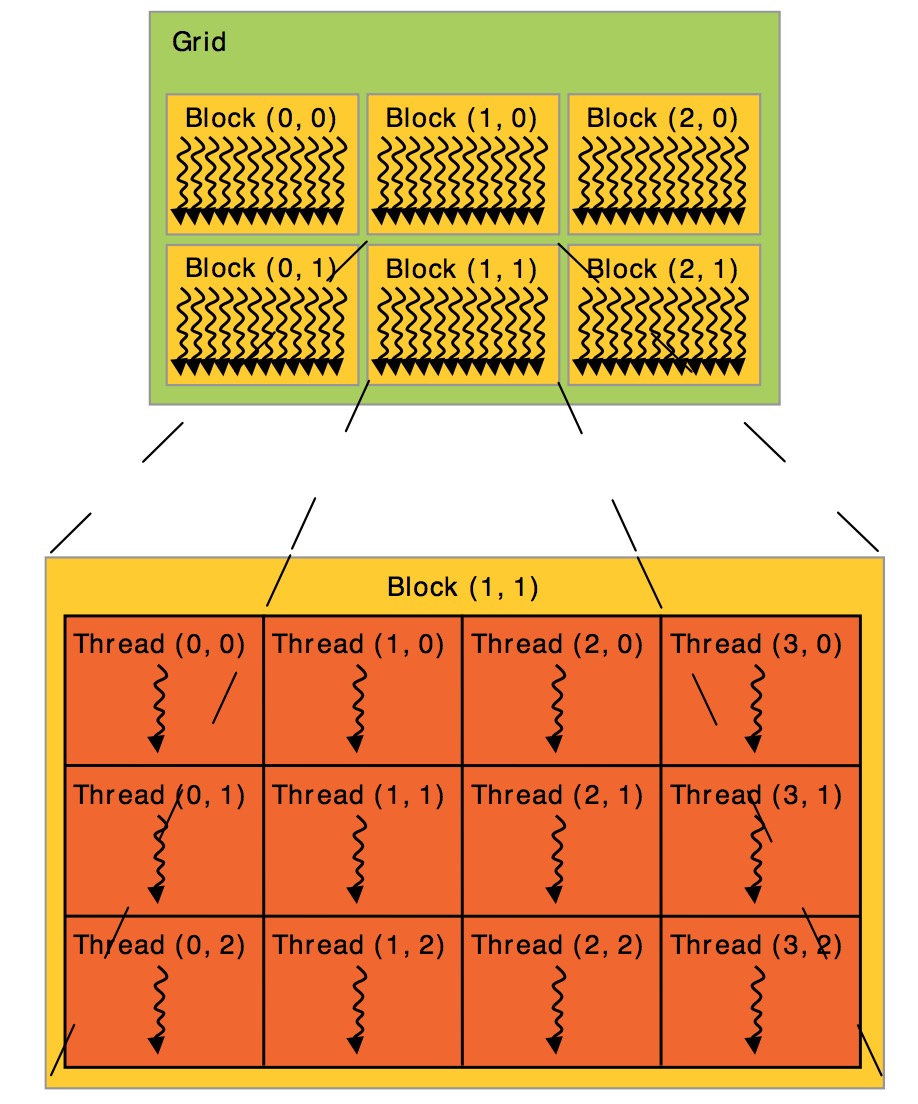
每个块(Block)所能包含的线程(Thread)数量是有限制的,因为目前每个块内的所有线程都是在一个物理的处理器核中,并且共享了这个核有限的内存资源。当前的GPU中,每个块最多能执行1024个线程。
There is a limit to the number of threads per block, since all threads of a block are expected to reside on the same processor core and must share the limited memory resources of that core. On current GPUs, a thread block may contain up to 1024 threads
多个Blocks可以组成1维、2维或者3维的Grid。kernel函数可以访问grid内部标识block的内置变量blockIdx,也可以访问表示block维度的内置变量blockDim.
Blocks are organized into a one-dimensional, two-dimensional, or three-dimensional grid of thread blocks.The number of thread blocks in a grid is usually dictated by the size of the data being processed or the number of processors in the system, which it can greatly exceed.
- thread index的计算
根据thread、block、grid的维度不同,thread index的计算方式也不一样。这时考虑两种简单的情况:
(1) grid划分成1维,block划分为1维
int threadId = blockIdx.x *blockDim.x + threadIdx.x;
(2) grid划分成1维,block划分为2维
int threadId = blockIdx.x * blockDim.x * blockDim.y+ threadIdx.y * blockDim.x + threadIdx.x;
注意,如果将threadIdx看做一个2维矩阵的话,threadIdx.y确定行号,而threadIdx.x确定列号。
在调用kernel函数可以通过<<<...>>>指定每个block的threads的数量,以及每个grid的blocks数量,例如:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
GPU中的这种多维的线程结构,可以让线程非常方便的索引它需要处理的向量、矩阵、或者立方体数据结构的元素。
GPU线程的映射
CUDA thread最终由实际的物理硬件计算单元执行,这里看看thread是如何映射到硬件单元的。先重复一下几个概念。
- 基本概念
| 简称 | 全称 | 注释 |
|---|---|---|
| SM | Stream Multiprocessor | 实际上对应一个CUDA core |
| SP | Stream Processor | 每个SM包含若干个SP, 由SM取指, 解码, 发射到各个SP, GPU可看作是一组SM |
- 映射关系
CUDA线程与硬件的具体的映射关系如下:
Thread -> SP Block -> SM Grid -> GPU
值得注意的是虽然Block映射到SM,但两者并不需要一一对应的关系。Blocks可以由任意数量的SM以任意的顺序调度,然后彼此独立的并行或者串行执行。这样,使得硬件的SM能够适应任意数量的CUDA block。
内存层次 (Thread Hierarchy)
CUDA threads在执行时,可以访问多个memory spaces,每个线程有自己的私有的local memory。每个block有一个shared memory,block的所有线程都可以访问。最后,所有线程都可以访问global memory。
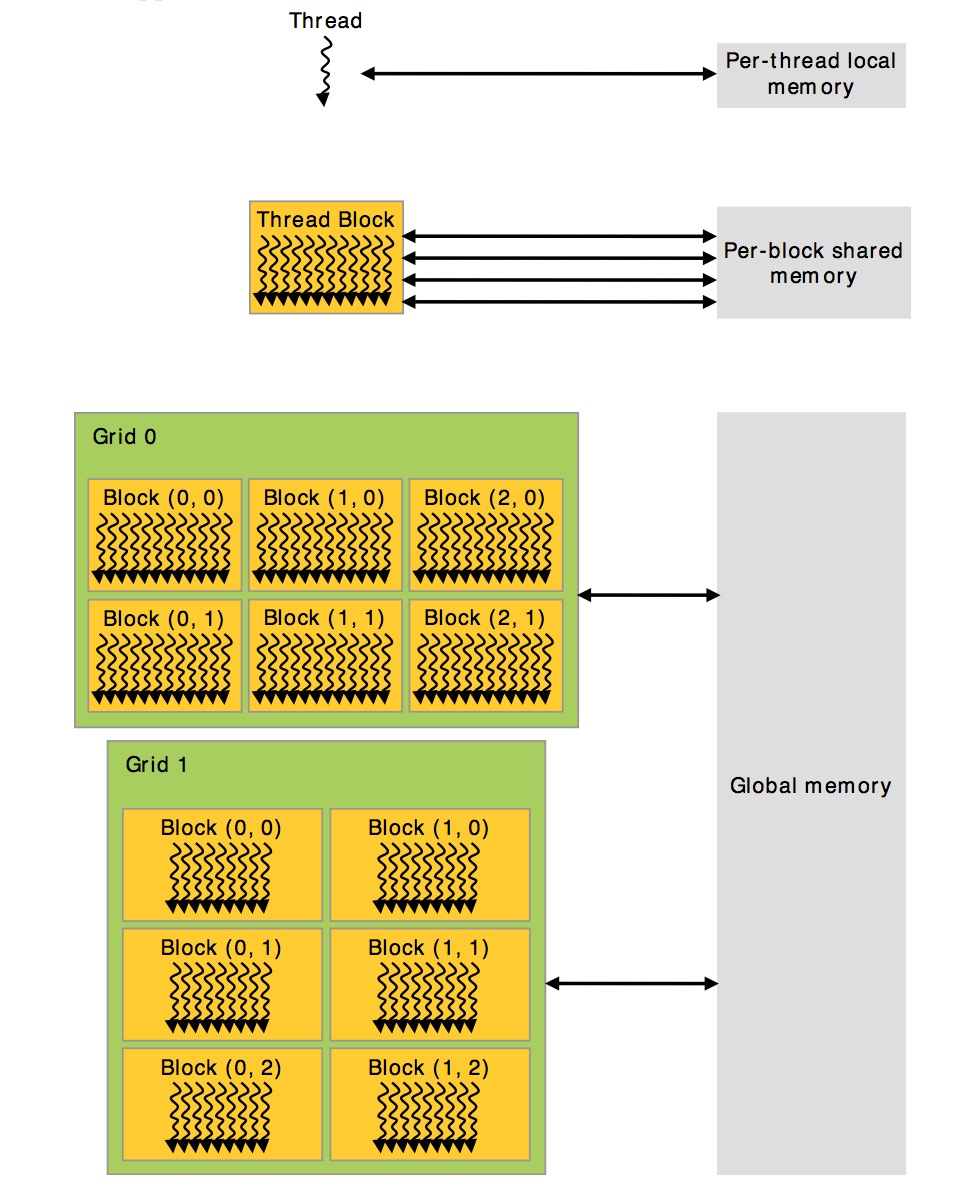
不同的内存访问速度如下:
本地内存 > 共享内存 > 全局内存
通过cudaMalloc分配的内存就是全局内存。核函数中用__shared__修饰的变量就是共享内存。 核函数定义的变量使用的就是本地内存。