1 问题
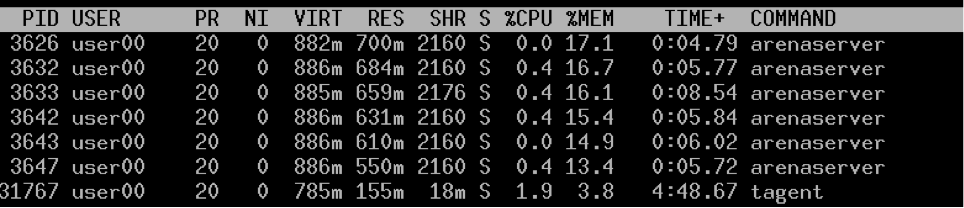
业务同样的程序跑在TDocker、XEN,占用的内存却相差很大。
TDocker:
XEN:
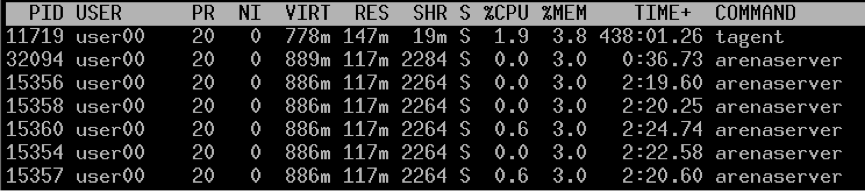
可以看到,虽然VIRT一样,但是程序占用的物理内存却相差6倍。
2 原因分析
经过各种分析,后来levy同学发现关闭transparent hugepage就解决了这个问题。TDocker使用的CentOS6.5的内核,默认开启了transparent hugepage。
# cat /sys/kernel/mm/redhat_transparent_hugepage/enabled
[always] madvise never
关闭transparent hugepage,
#echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled
#echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
重启业务程序,马上见效:

那么问题来了,为什么hugepage会导致程序使用的物理内存会多那么多呢?
从业务同学了解到,该程序在启动时加载用户的排行榜到内存中,数据保存到一个std::map中,每个Server 1W人,应该不会占用到那么多物理内存:
map<string, ...> m_mUserRank
由于hugepage使用2M的PAGE,
# cat /proc/meminfo |grep Hugepagesize
Hugepagesize: 2048 Kb
所以每次缺页都会导致内核分配2M的内存,而不是4K。如果程序访问内存不连续,必然导致物理内存过多分配,而C++ map符合这种情况。
下面通过一个测试程序来验证这一想法。
3 测试
程序的想法很简单,申请800M的(虚拟)内存,然后以2M为单位,每次只写4K。
/* gcc -o hugepage hugepage.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define BUF_SIZE 838860800
#define STEP 2097152 //2MB
int main(){
int i = 0, count = 0;
char *p = (char*)malloc(BUF_SIZE);
sleep(15);
printf("start memset\n");
for(i = 0; i < BUF_SIZE; i++){
memset(p + i, 0, 4096);
i += STEP;
count++;
}
printf("done, count=%d\n", count);
sleep(60);
return 0;
}
运行:
# ./hugepage
start memset
done, count=400
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
64617 root 20 0 803m 798m 360 S 0.0 1.2 0:00.18 hugepage
可以看到,虽然只写了400 * 4K =1600K的数据,进程却使用了798M物理内存,相差700倍。
关闭hugepage
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7161 root 20 0 803m 3676 400 S 0.0 0.0 0:00.00 hugepage
可以看到,同样的程序只使用了10M多内存。
4 总结
Transparent Hugepage是由Andrea Arcangeli提交并在2.6.38合到内核的特性,这对于使用大内存的程序,可以减少TLB miss的次数,据说能带来10%的性能提升。
但是,由于PAGE size变成2M,这也可能带来负面的影响,可能导致程序占用的物理内存比4K的page size情况下要多。当然,前提是程序申请了过多的内存,却没有使用到这些内存。
主要参考
- http://lwn.net/Articles/359158/
- https://lwn.net/Articles/423584/
- https://www.kernel.org/doc/Documentation/vm/transhuge.txt
- http://www.slideshare.net/raghusiddarth/transparent-hugepages-in-rhel-6