PID namespace
PID namespace在2.6.24由OpenVZ团队加入内核,不同PID namespace的进程ID是独立的。PID namespace最初是为了解决容器的热迁移的问题:
This feature is the major prerequisite for the migration of containers between hosts; having a namespace, one may move it to another host while keeping the PID values – and this is a requirement since a task is not expected to change its PID. Without this feature, the migration will very likely fail, as the processes with the same IDs can exist on the destination node, which will cause conflicts when addressing tasks by their IDs.
参考这里.
进程ID
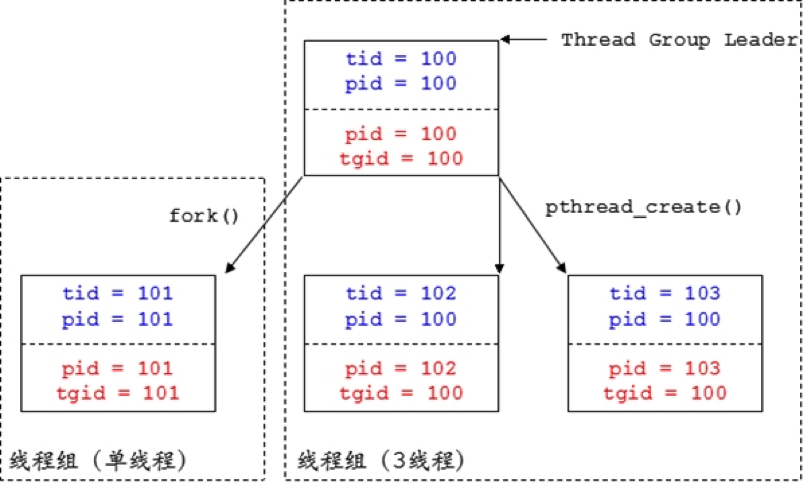
我们知道,在Linux中是用进程来模拟线程:
-
(1)单线程的进程就是该进程自身,用户看到的线程TID和PID实际上都是内核中进程的PID。
-
(2)多线程的进程实际上是一组进程(进程数和线程数相同),称为Thread Group(线程组),该线程组中的每个进程(线程)有各自的PID和统一的TGID。用户使用gettid()来获取线程的TID时,内核实际返回的是进程的PID;使用getpid()获取线程的公共PID时,内核返回的是进程的TGID。TGID实际上就是Thread Group Leader(最早存在的进程)的PID。
** 注意,进程组与线程组的区别?**
参考这里
假设一个进程先fork()一次,再pthread_create()两次,大概的关系图如下所示(蓝色字体表示应用层,红色字条表示内核):
由于PID namespace 的引入,进程ID变得稍稍复杂:
-
(1)全局ID为进程在内核本身和init namespace的唯一ID,即init进程的namespace的ID。
-
(2)局部ID为进程在某个特定namespace中的ID。对每个ID类型,它们在所属的namespace内部有效,但类型相同、值也相同的ID可能出现在不同的命名空间中。
task_struct有4种PID:the process ID (PID), the thread group ID(TGID), the process group ID (PGID), and the session ID (SID)。同一个group的进程会共享PGID和SID。
全局PID和TGID保存在task_struct中,分别是task_struct的pid和tgid成员。
主要数据结构
** task_struct **
struct task_struct {
...
pid_t pid; ///全局pid, p->pid = pid_nr(pid);
pid_t tgid; ///全局线程组ID
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct *real_parent; /* real parent process */
struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader,线程组leader */
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];///PID
struct list_head thread_group; ///线程链表
加入namespace后,task_struct的pid/tgid字段用于描述进程在全局的ID,即init_ns中的ID。
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
...
///全局进程ID
p->pid = pid_nr(pid);
p->tgid = p->pid; ///全局TGID
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid; ///如果是线程,则指定进程的TGID
** pid_namespace **
#define PIDMAP_ENTRIES ((PID_MAX_LIMIT + 8*PAGE_SIZE - 1)/PAGE_SIZE/8) ///PAGE数量
struct pid_namespace {
struct pidmap pidmap[PIDMAP_ENTRIES]; ///每个进程一个bit
int last_pid;
struct task_struct *child_reaper; ///reaper进程
unsigned int level; ///层级
struct pid_namespace *parent; ///父namespace
** pid **
/* linux/pid.h
* struct upid is used to get the id of the struct pid, as it is
* seen in particular namespace. Later the struct pid is found with
* find_pid_ns() using the int nr and struct pid_namespace *ns.
*/
///描述进程在特定namespace中的ID
struct upid {
/* Try to keep pid_chain in the same cacheline as nr for find_vpid */
int nr; //在分层中的PID(局部ID)
struct pid_namespace *ns;
struct hlist_node pid_chain; //pid_hash
};
struct pid
{
atomic_t count;
unsigned int level; //进程的pid namespace层数
/* lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX];///进程内的所有线程共享同一个struct pid?
struct rcu_head rcu;
struct upid numbers[1]; //一个进程可能在多个namespace中可见
};
** pid_type **
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};
注意,这里并不包含线程组ID!因为线程组ID实际上就是线程组组长的PID,所以没有必要另外单独定义。
* 如何遍历PID namespace中的所有进程?比如在procfs中显示当前namespace中所有的进程?*
通过pid_namespace->pid_map找到进程的nr,通过find_pid_ns找到struct pid,pid_task返回pid->tasks[type]的第一个task_struct结构。
** nr -> task_struct **
分两步:
- (1)nr -> struct pid
通过nr可以在pid_hash中找到struct upid,然后通过container_of返回struct pid。
struct pid *find_pid_ns(int nr, struct pid_namespace *ns)
{
struct hlist_node *elem;
struct upid *pnr;
hlist_for_each_entry_rcu(pnr, elem,
&pid_hash[pid_hashfn(nr, ns)], pid_chain)
if (pnr->nr == nr && pnr->ns == ns)
return container_of(pnr, struct pid,
numbers[ns->level]);
return NULL;
}
- (2)struct pid -> task
通过函数pid_task返回pid->tasks[type] 散列表中的第一个task_struct实例。
struct task_struct *find_task_by_pid_ns(pid_t nr, struct pid_namespace *ns)
{
return pid_task(find_pid_ns(nr, ns), PIDTYPE_PID);
}
** task -> nr **
分两步:
- (1)task -> struct pid
static inline struct pid *task_pid(struct task_struct *task)
{
return task->pids[PIDTYPE_PID].pid;
}
- (2)struct pid -> nr
返回struct pid在特定namespace对应的nr:
pid_t pid_nr_ns(struct pid *pid, struct pid_namespace *ns)
{
struct upid *upid;
pid_t nr = 0;
if (pid && ns->level <= pid->level) {
upid = &pid->numbers[ns->level];
if (upid->ns == ns)
nr = upid->nr;
}
return nr;
}
因为祖先namespace可以看到子namespace的PID,反过来却不行,所以指定的namespace(ns)的level<=PID的namepace的level(这样才能保证在ns中PID是可见的)。
pid_nvr返回进程在当前namespace的局部ID,比如在sys_getpid
pid_t pid_vnr(struct pid *pid)
{
return pid_nr_ns(pid, task_active_pid_ns(current));
}
函数pid_nr返回全局ID:
/*
* the helpers to get the pid's id seen from different namespaces
*
* pid_nr() : global id, i.e. the id seen from the init namespace;
* pid_vnr() : virtual id, i.e. the id seen from the pid namespace of
* current.
* pid_nr_ns() : id seen from the ns specified.
*
* see also task_xid_nr() etc in include/linux/sched.h
*/
static inline pid_t pid_nr(struct pid *pid)
{
pid_t nr = 0;
if (pid)
nr = pid->numbers[0].nr;
return nr;
}
分配PID(struct pid)
分配PID,相当于从pid_namespace->pidmap寻找第一个值为0的bit,并将其置为1;反之释放PID,则将其从1置为0即可。这通过alloc_pidmap/free_pidmap完成。
struct pid *alloc_pid(struct pid_namespace *ns)
{
struct pid *pid;
enum pid_type type;
int i, nr;
struct pid_namespace *tmp;
struct upid *upid;
///分配数据结构
pid = kmem_cache_alloc(ns->pid_cachep, GFP_KERNEL);
if (!pid)
goto out;
///进程需要在多个namespace可见,所以从当前namespace,直到init_ns,每个namespace都要分配一个nr
tmp = ns;
pid->level = ns->level;
for (i = ns->level; i >= 0; i--) {
nr = alloc_pidmap(tmp);
if (nr < 0)
goto out_free;
pid->numbers[i].nr = nr; ///特定namespace的nr
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
if (unlikely(is_child_reaper(pid))) {
if (pid_ns_prepare_proc(ns))
goto out_free;
}
get_pid_ns(ns);
atomic_set(&pid->count, 1);
for (type = 0; type < PIDTYPE_MAX; ++type)
INIT_HLIST_HEAD(&pid->tasks[type]);
///每个namespace对应的upid都要加入全局pid_hash
upid = pid->numbers + ns->level;
spin_lock_irq(&pidmap_lock);
for ( ; upid >= pid->numbers; --upid) {
hlist_add_head_rcu(&upid->pid_chain,
&pid_hash[pid_hashfn(upid->nr, upid->ns)]);
upid->ns->nr_hashed++;
}
spin_unlock_irq(&pidmap_lock);
out:
return pid;
}
PID namespace与init进程
PID namespace中第一个进程的进程ID为1(在该namespace内),相当于该namespace的init进程:它可以做一些初始化工作,也可以成为该namespace的孤儿进程(orphanded)的父进程。
Signal与init进程
在Linux中,只能给init已经安装信号处理函数的信号,其它信号都会被忽略,这可以防止init进程被误杀掉,即使是superuser。所以,kill -9 init不会kill掉init进程。
PID namespace的init也一样。祖先PID namespace 的进程也只能给(子)PID namespace init进程发送已经安装的信号处理函数的信号,但是SIGKILL和SIGSTOP除外,也就是说,即使init进程没有安装SIGKILL/SIGSTOP信号处理函数,祖先PID namepsace也可以给init发送SIGKILL/SIGSTOP。
# ./ns_child_exec -p -m ./simple_init -v
init: my PID is 1
init$ mount -t proc proc /proc
init: created child 2
init: SIGCHLD handler: PID 2 terminated
init$ ps -ef
init: created child 3
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11:13 pts/0 00:00:00 ./simple_init -v
root 3 1 0 11:13 pts/0 00:00:00 ps -ef
init: SIGCHLD handler: PID 3 terminated
init$ kill -SIGKILL 1
init: created child 4
init: SIGCHLD handler: PID 4 terminated
init$ ps -ef
init: created child 5
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11:13 pts/0 00:00:00 ./simple_init -v
root 5 1 0 11:13 pts/0 00:00:00 ps -ef
init: SIGCHLD handler: PID 5 terminated
可以看到,在PID namespace内部给init进程发送SIGKILL,对init没有影响。
# ps -ef|grep simple_init
root 2252 1756 0 11:13 pts/0 00:00:00 ./ns_child_exec -p -m ./simple_init -v
root 2253 2252 0 11:13 pts/0 00:00:00 ./simple_init -v
# kill -SIGTERM 2253 #simple_init没有影响
# kill -SIGKILL 2253 #simple_init退出
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
...
if (likely(p->pid)) {
list_add_tail(&p->sibling, &p->real_parent->children);
tracehook_finish_clone(p, clone_flags, trace);
///进程是当前PID namepsace的init(1)进程,则将PID namespace的chile_reaper设置为p
if (thread_group_leader(p)) {
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE; ///init进程不能发送SIG_KILL
}
p->signal->leader_pid = pid;
如果PID namespace中的init进程被kill掉(SIGKILL),内核会给该init的所有其它进程发送SIGKILL。当init结束时,PID namespace也会被释放,但是也有例外,如果/proc/
参考这里。
Zap namespace
当PID namespace中的init进程结束时,会销毁对应的PID namespace,并向所有其它的子进程发送SIGKILL。这也是为什么当我们手动kill掉容器的第一个init进程,容器会自动结束。
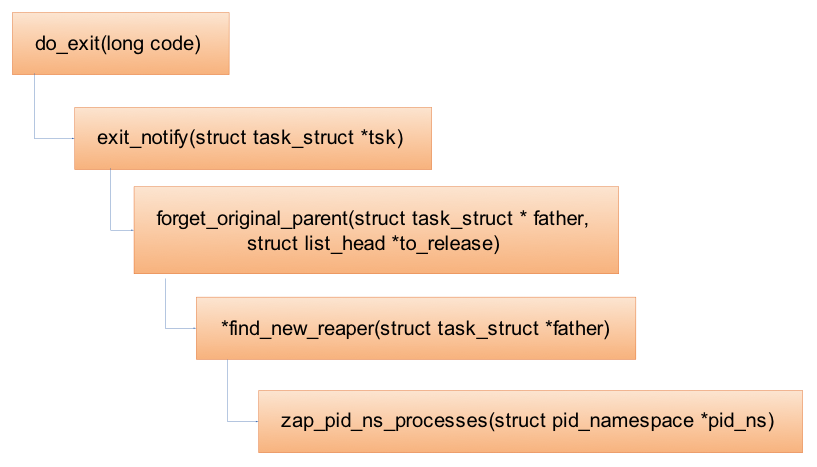
///销毁pid namespace
void zap_pid_ns_processes(struct pid_namespace *pid_ns)
{
int nr;
int rc;
struct task_struct *task;
/*
* The last thread in the cgroup-init thread group is terminating.
* Find remaining pid_ts in the namespace, signal and wait for them
* to exit.
*
* Note: This signals each threads in the namespace - even those that
* belong to the same thread group, To avoid this, we would have
* to walk the entire tasklist looking a processes in this
* namespace, but that could be unnecessarily expensive if the
* pid namespace has just a few processes. Or we need to
* maintain a tasklist for each pid namespace.
*
*/
read_lock(&tasklist_lock);
nr = next_pidmap(pid_ns, 1); ///取namespace中的下一个nr
while (nr > 0) {
rcu_read_lock();
/*
* Use force_sig() since it clears SIGNAL_UNKILLABLE ensuring
* any nested-container's init processes don't ignore the
* signal
*/ ///根据nr找到对应的task_struct结构
task = pid_task(find_vpid(nr), PIDTYPE_PID);
if (task)
force_sig(SIGKILL, task); ///会清除SIGNAL_UNKILLABLE标志
rcu_read_unlock();
nr = next_pidmap(pid_ns, nr);
}
read_unlock(&tasklist_lock);
do {
clear_thread_flag(TIF_SIGPENDING);
rc = sys_wait4(-1, NULL, __WALL, NULL); ///等待所有子进程退出
} while (rc != -ECHILD);
if (pid_ns->reboot)
current->signal->group_exit_code = pid_ns->reboot;
acct_exit_ns(pid_ns);
return;
}
Mount procfs
在Linux中,每个进程在procfs都有一个目录,例如/proc/
init$mount -t proc proc /proc
其实像ps这类的工具都是从/proc获取进程的信息。
init$ ps -ef
init: created child 8
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11:27 pts/0 00:00:00 ./simple_init -v
root 8 1 0 11:43 pts/0 00:00:00 ps -ef
init: SIGCHLD handler: PID 8 terminated
只列出了当前PID namespace中的进程。
- update@2015/6/19 *
今天一个业务同学发现在ps -ef不能看到的pid,在/proc目录下也没有对应的目录,但却可以cd /proc/$pid。后来我发现原来所谓的pid是mysqld的一个线程。也就是说,对于线程,ls /proc/不会列出对应的目录,但实际上这个目录是存在的。后面找时间看看这里的实现??
unshare与setns
系统调用unshare用于创建新的(PID)namespace,setns用于将进程加入到已经存在的namespace(/proc/
# ./ns_child_exec -p ./simple_init -v
init: my PID is 1
init$ init: SIGCHLD handler: PID 3 terminated
# ps -ef|grep simple
root 2362 1756 0 11:56 pts/0 00:00:00 ./ns_child_exec -p ./simple_init -v
root 2363 2362 0 11:56 pts/0 00:00:00 ./simple_init -v
# ./ns_run -f -n /proc/2363/ns/pid ./orphan
Parent (PID=2) created child with PID 3
Parent (PID=2; PPID=0) terminating
Child (PID=3) now an orphan (parent PID=1)
Child (PID=3) terminating
进程ns_run创建orphan(parent),orphan(parent)创建orphan(child),关系如下图所示:
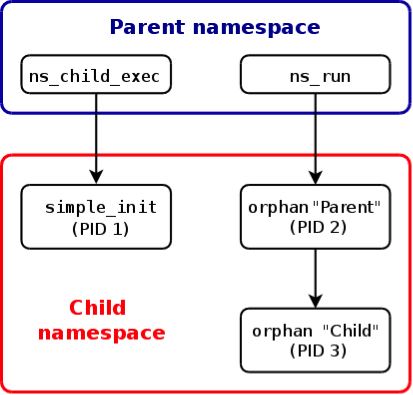
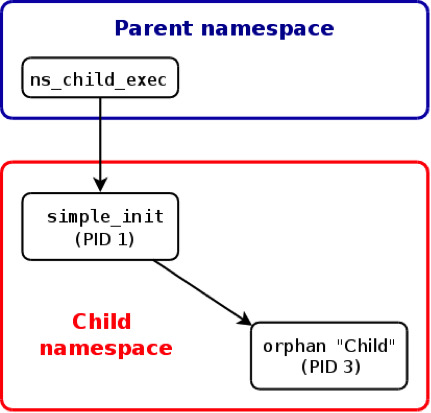
orphan(parent)和orphan(child)都在simple_init创建的PID namespace,而ns_run还是在原来的namespace。另外,值得注意的是orphan(parent)的父进程为0(PPID=0),这是因为ns_run在当前namespace不可见,所以PPID=0。
当orphan(parent)退出之后,orphan(child)的父进程变成simple_init,simple_init收到orphan(child)退出的信号SIGCHILD。
测试程序代码
主要参考
- Namespaces in operation, part 3: PID namespaces
- Namespaces in operation, part 4: more on PID namespaces
- PID namespaces in the 2.6.24 kernel
Docker容器init进程
容器的第一个进程为容器的init进程。容器的启动过程实际上就创建容器init进程的过程:
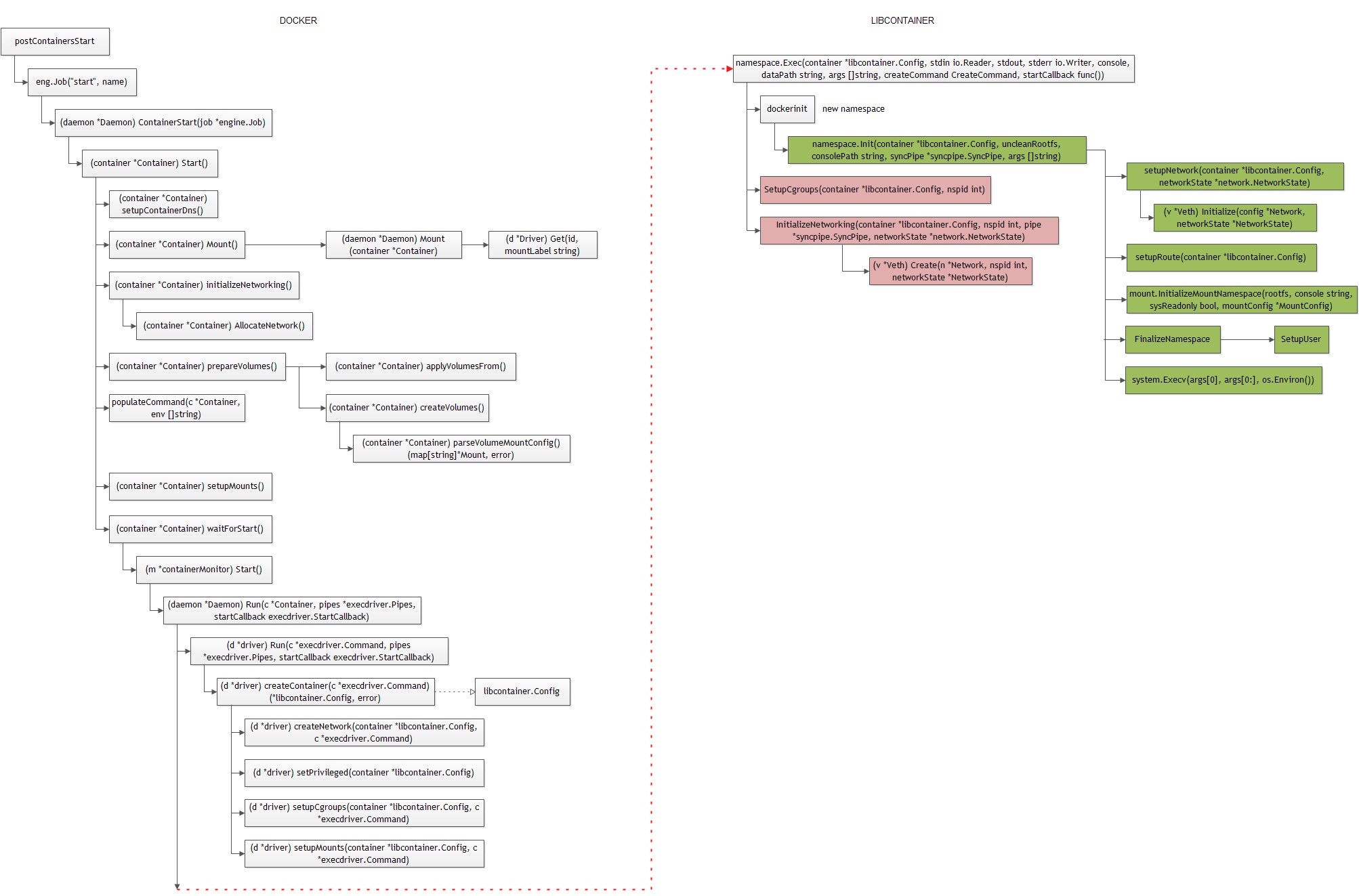
创建exec.Cmd
启动容器的init进程:
// TODO(vishh): This is part of the libcontainer API and it does much more than just namespaces related work.
// Move this to libcontainer package.
// Exec performs setup outside of a namespace so that a container can be
// executed. Exec is a high level function for working with container namespaces.
func Exec(container *libcontainer.Config, stdin io.Reader, stdout, stderr io.Writer, console, dataPath string, args []string, createCommand CreateCommand, startCallback func()) (int, error) {
...
///返回os/exec.Cmd对象
command := createCommand(container, console, dataPath, os.Args[0], syncPipe.Child(), args)
// Note: these are only used in non-tty mode
// if there is a tty for the container it will be opened within the namespace and the
// fds will be duped to stdin, stdiout, and stderr
command.Stdin = stdin
command.Stdout = stdout
command.Stderr = stderr
///执行exec.Cmd
if err := command.Start(); err != nil {
return -1, err
}
...
基本过程:
- (1)调用createCommand返回exec.Cmd对象:
type Cmd struct {
// Path is the path of the command to run.
//
// This is the only field that must be set to a non-zero
// value. If Path is relative, it is evaluated relative
// to Dir.
Path string ///执行程序路径
// Args holds command line arguments, including the command as Args[0].
// If the Args field is empty or nil, Run uses {Path}.
//
// In typical use, both Path and Args are set by calling Command.
Args []string ///传给执行程序的参数
…
// SysProcAttr holds optional, operating system-specific attributes.
// Run passes it to os.StartProcess as the os.ProcAttr's Sys field.
SysProcAttr *syscall.SysProcAttr ///clone参数
…
- (2)执行exec.Cmd。
exec.Cmd有两个字段,Path指定执行程序路径,Args指定参数。
createCommand函数:
主要完成ProcessConfig.Cmd的赋值:
func(container *libcontainer.Config, console, dataPath, init string, child *os.File, args []string) *exec.Cmd {
c.ProcessConfig.Path = d.initPath ///exec.Cmd.Path
c.ProcessConfig.Args = append([]string{
DriverName,
"-console", console,
"-pipe", "3",
"-root", filepath.Join(d.root, c.ID),
"--",
}, args...)
// set this to nil so that when we set the clone flags anything else is reset
c.ProcessConfig.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: uintptr(namespaces.GetNamespaceFlags(container.Namespaces)),
}///clone参数,创建新的namespace
c.ProcessConfig.ExtraFiles = []*os.File{child}
c.ProcessConfig.Env = container.Env
c.ProcessConfig.Dir = container.RootFs
///返回exec.Cmd
return &c.ProcessConfig.Cmd
}
实际上,exec.Cmd相当于下面的命令:
initPath: /data/docker/init/dockerinit-1.3.6
Args:[native -console -pipe 3 -root /data/docker/execdriver/native/$id – /bin/sh -c /sbin/init]
init: /usr/bin/docker
由于在创建子进程时,指定了exec.Cmd.SysProcAttr,这会创建新的namespace(network、mount 、ipc、pid、uts)。
* 另外,注意到createCommand并没有使用参数init。*
dockerinit
dockerinit的路径保存在native.driver.initPath:
//native/driver.go
type driver struct {
root string
initPath string
activeContainers map[string]*activeContainer
sync.Mutex
}
func NewDriver(root, initPath string) (*driver, error) {
...
return &driver{
root: root,
initPath: initPath, ///dockerinit路径
activeContainers: make(map[string]*activeContainer),
}, nil
}
docker daemon在启动时,如果发现没有$ROOT/init/dockerinit_$VERION程序时,就会拷贝docker到$ROOT/init/dockerinit_$VERION:
//daemon/daemon.go
func NewDaemonFromDirectory(config *Config, eng *engine.Engine) (*Daemon, error) {
...
localCopy := path.Join(config.Root, "init", fmt.Sprintf("dockerinit-%s", dockerversion.VERSION))
sysInitPath := utils.DockerInitPath(localCopy)
if sysInitPath == "" {
return nil, fmt.Errorf("Could not locate dockerinit: This usually means docker was built incorrectly. See http://docs.docker.com/contributing/devenvironment for official build instructions.")
}
if sysInitPath != localCopy {
// When we find a suitable dockerinit binary (even if it's our local binary), we copy it into config.Root at localCopy for future use (so that the original can go away without that being a problem, for example during a package upgrade).
if err := os.Mkdir(path.Dir(localCopy), 0700); err != nil && !os.IsExist(err) {
return nil, err
}
if _, err := utils.CopyFile(sysInitPath, localCopy); err != nil {
return nil, err
}
if err := os.Chmod(localCopy, 0700); err != nil {
return nil, err
}
sysInitPath = localCopy
}
///create execdriver
sysInfo := sysinfo.New(false)
ed, err := execdrivers.NewDriver(config.ExecDriver, config.Root, sysInitPath, sysInfo)
if err != nil {
return nil, err
}
Run exec.Cmd
封装好exec.Cmd对象后,接下来就是要运行exec.Cmd(即dockerinit),并一直等待子进程结束。从这里可以看到,docker daemon做为dockerinit的父进程,并且一直等待容器退出,并且获取其退出码。
func Exec(container *libcontainer.Config, stdin io.Reader, stdout, stderr io.Writer, console, dataPath string, args []string, createCommand CreateCommand, startCallback func()) (int, error) {
///exec.Cmd
command := createCommand(container, console, dataPath, os.Args[0], syncPipe.Child(), args)
command.Stdin = stdin
command.Stdout = stdout
command.Stderr = stderr
///run exec.Cmd
if err := command.Start(); err != nil {
return -1, err
}
///与dockerinit同步,等待dockerinit启动
// Sync with child
if err := syncPipe.ReadFromChild(); err != nil {
command.Process.Kill()
command.Wait()
return -1, err
}
if startCallback != nil {
startCallback()
}
///等待容器的init进程退出
if err := command.Wait(); err != nil {
if _, ok := err.(*exec.ExitError); !ok {
return -1, err
}
}
///返回容器的退出码
return command.ProcessState.Sys().(syscall.WaitStatus).ExitStatus(), nil
引导init
docker执行/data/docker/init/dockerinit-1.3.6 native -console -pipe 3 -root /data/docker/execdriver/native/$id – /bin/sh -c /sbin/init命令,通过dockerinit来引导执行用户指定的init进程,作为容器的init进程:
//docker/docker.go
func main() {
if reexec.Init() { //
return
}
...
//pkg/reexec/reexec.go
// Init is called as the first part of the exec process and returns true if an
// initialization function was called.
func Init() bool {
initializer, exists := registeredInitializers[os.Args[0]]
if exists {
initializer()
return true
}
return false
}
execdriver注册initializer函数:
//execdriver/native/init.go
func init() {
reexec.Register(DriverName, initializer) ///native
}
func initializer() {
...
if err := namespaces.Init(container, rootfs, *console, syncPipe, flag.Args()); err != nil {
writeError(err)
}
}
函数namespaces.Init完成容器的初始化(网络、mount namespace),然后通过系统调用execv执行用户指定的init进程。
/////libcontainer/namespaces/init.go
// Init is the init process that first runs inside a new namespace to setup mounts, users, networking,
// and other options required for the new container.
// The caller of Init function has to ensure that the go runtime is locked to an OS thread
// (using runtime.LockOSThread) else system calls like setns called within Init may not work as intended.
func Init(container *libcontainer.Config, uncleanRootfs, consolePath string, syncPipe *syncpipe.SyncPipe, args []string) (err error) {
....
///等待docker daemon进程创建好veth pair
// We always read this as it is a way to sync with the parent as well
var networkState *network.NetworkState
if err := syncPipe.ReadFromParent(&networkState); err != nil {
return err
}
...
///网络初始化
if err := setupNetwork(container, networkState); err != nil {
return fmt.Errorf("setup networking %s", err)
}
...
///文件系统初始化
if err := mount.InitializeMountNamespace(rootfs,
consolePath,
container.RestrictSys,
(*mount.MountConfig)(container.MountConfig)); err != nil {
return fmt.Errorf("setup mount namespace %s", err)
}
...
///执行用户指定的程序
return system.Execv(args[0], args[0:], os.Environ())
}
父子进程通过socketpair进行同步通信。
** 网络初始化 **
Docker默认使用veth,daemon进程创建好veth pair后,将veth device name传给容器的init进程,init进程完成IP、MAC、MTU、Gateway等信息的设置:
// Struct describing the network specific runtime state that will be maintained by libcontainer for all running containers
// Do not depend on it outside of libcontainer.
type NetworkState struct {
// The name of the veth interface on the Host.
VethHost string `json:"veth_host,omitempty"`
// The name of the veth interface created inside the container for the child.
VethChild string `json:"veth_child,omitempty"`
// Net namespace path.
NsPath string `json:"ns_path,omitempty"`
}
func setupNetwork(container *libcontainer.Config, networkState *network.NetworkState) error {
for _, config := range container.Networks {
strategy, err := network.GetStrategy(config.Type)
if err != nil {
return err
}
///参考(v *Veth) Initialize
err1 := strategy.Initialize((*network.Network)(config), networkState)
if err1 != nil {
return err1
}
}
return nil
}
** 文件系统初始化 **
///mount/init.go
InitializeMountNamespace
ProcessConfig
描述容器的init进程:
// Describes a process that will be run inside a container.
type ProcessConfig struct {
exec.Cmd `json:"-"`
Privileged bool `json:"privileged"`
User string `json:"user"`
Tty bool `json:"tty"`
Entrypoint string `json:"entrypoint"`
Arguments []string `json:"arguments"`
Terminal Terminal `json:"-"` // standard or tty terminal
Console string `json:"-"` // dev/console path
}
ProcessConfig有两个地方赋值:
- (1) populateCommand
Container->start() → populateCommand
func populateCommand(c *Container, env []string) error {
。。。
processConfig := execdriver.ProcessConfig{
Privileged: c.hostConfig.Privileged,
Entrypoint: c.Path,
Arguments: c.Args,
Tty: c.Config.Tty,
User: c.Config.User,
}
processConfig.SysProcAttr = &syscall.SysProcAttr{Setsid: true}
processConfig.Env = env
- (2)createCommand函数主要完成ProcessConfig.Cmd的赋值。
Docker exec
Docker命令docker exec可以在指定的容器内部执行指定的命令。想在容器内部执行命令,首先需要进入到容器的namespace(network、pid、ipc、mount、uts),其次需要将执行的命令进程加入到容器对应的cgroup。
流程
命令的整个实现流程如下:
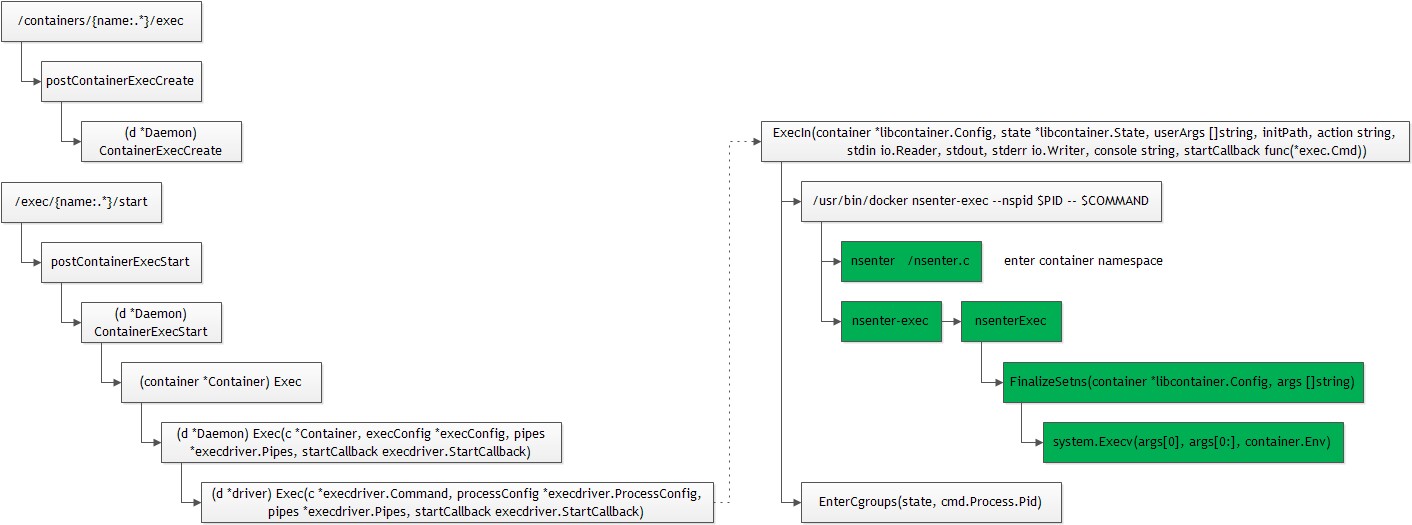
[debug] server.go:1226 Calling POST /containers/{name:.*}/exec
[info] POST /v1.15/containers/vm1/exec
[3e70fc25] +job execCreate(vm1)
[3e70fc25] -job execCreate(vm1) = OK (0)
[debug] server.go:1226 Calling POST /exec/{name:.*}/start
[info] POST /v1.15/exec/b3f1e0b8e0a781290049fa255ad2ff6dcf6d0f26ff5a8614702abd916ca8a489/start
[3e70fc25] +job execStart(b3f1e0b8e0a781290049fa255ad2ff6dcf6d0f26ff5a8614702abd916ca8a489)
[debug] exec.go:179 starting exec command b3f1e0b8e0a781290049fa255ad2ff6dcf6d0f26ff5a8614702abd916ca8a489 in container 7cd458e8f9946680dcac28a3fbe47a2ba58710623921f24d4b619cf91381d8eb
[debug] attach.go:176 attach: stdout: begin
[debug] attach.go:215 attach: stderr: begin
[debug] attach.go:263 attach: waiting for job 1/2
2015/06/17 16:28:54 init path: /usr/bin/docker with args: [nsenter-exec --nspid 5982 -- ls /]
[debug] exec.go:282 Exec task in container 7cd458e8f9946680dcac28a3fbe47a2ba58710623921f24d4b619cf91381d8eb exited with code 0
[debug] attach.go:193 attach: stdout: end
[debug] attach.go:233 attach: stderr: end
[debug] attach.go:268 attach: job 1 completed successfully
[debug] attach.go:263 attach: waiting for job 2/2
[debug] attach.go:268 attach: job 2 completed successfully
[debug] attach.go:270 attach: all jobs completed successfully
[3e70fc25] -job execStart(b3f1e0b8e0a781290049fa255ad2ff6dcf6d0f26ff5a8614702abd916ca8a489) = OK (0)
// TODO(vishh): Add support for running in priviledged mode and running as a different user.
func (d *driver) Exec(c *execdriver.Command, processConfig *execdriver.ProcessConfig, pipes *execdriver.Pipes, startCallback execdriver.StartCallback) (int, error) {
...
///user command
args := append([]string{processConfig.Entrypoint}, processConfig.Arguments...)
return namespaces.ExecIn(active.container, state, args, os.Args[0], "exec", processConfig.Stdin, processConfig.Stdout, processConfig.Stderr, processConfig.Console,
func(cmd *exec.Cmd) {
if startCallback != nil {
startCallback(&c.ProcessConfig, cmd.Process.Pid)
}
})
}
// ExecIn reexec's the initPath with the argv 0 rewrite to "nsenter" so that it is able to run the
// setns code in a single threaded environment joining the existing containers' namespaces.
func ExecIn(container *libcontainer.Config, state *libcontainer.State, userArgs []string, initPath, action string,
stdin io.Reader, stdout, stderr io.Writer, console string, startCallback func(*exec.Cmd)) (int, error) {
args := []string{fmt.Sprintf("nsenter-%s", action), "--nspid", strconv.Itoa(state.InitPid)}
if console != "" {
args = append(args, "--console", console)
}
cmd := &exec.Cmd{
Path: initPath, ///usr/bin/docker
Args: append(args, append([]string{"--"}, userArgs...)...), ///nsenter-exec --nspid $PID -- $COMMAND
}
…
initPath: /usr/bin/docker
Args: nsenter-exec –nspid $PID – $COMMAND
nsenter-exec的实现
nsenter-exec实现在容器的namespace运行用户指定的命令。其实现与Docker启动init进程的方式相同,调用nsenter-exec注册的initializer函数:
//execdriver/native/exec.go
const execCommandName = "nsenter-exec"
func init() {
reexec.Register(execCommandName, nsenterExec)
}
func nsenterExec() {
runtime.LockOSThread()
// User args are passed after '--' in the command line.
userArgs := findUserArgs() ///user command
config, err := loadConfigFromFd()
if err != nil {
log.Fatalf("docker-exec: unable to receive config from sync pipe: %s", err)
}
///run user command in container namespace
if err := namespaces.FinalizeSetns(config, userArgs); err != nil {
log.Fatalf("docker-exec: failed to exec: %s", err)
}
}
FinalizeSetns
FinalizeSetns运行指定的命令:
//libcontainer/namespaces/execin.go
// Finalize expects that the setns calls have been setup and that is has joined an
// existing namespace
func FinalizeSetns(container *libcontainer.Config, args []string) error {
...
///run user command
if err := system.Execv(args[0], args[0:], container.Env); err != nil {
return err
}
panic("unreachable")
}
* 何时进入容器的namespace?*
上面的代码找不到进入容器namespace的逻辑。Docker这里借助了golang的init函数,在执行main函数之前,执行下面的函数:
//namespaces/nsenter/nsenter.go
package nsenter
/*
__attribute__((constructor)) init() {
nsenter();
}
*/
import "C"
nsenter是一个C函数,实现进入到指定pid的namespace:
#mv /usr/bin/docker /usr/bin/nsenter-exec
# nsenter-exec help
nsenter --nspid <pid> --console <console> -- cmd1 arg1 arg2...
主要参考
- http://lwn.net/Articles/532748/