1 现象
之前,XFS上跑MySQL时,发现了一个XFS的性能问题,参考这里。后来发现即使改成了direct IO,有时性能还是很差,从iostat就可以看出:
- 性能正常的时候:
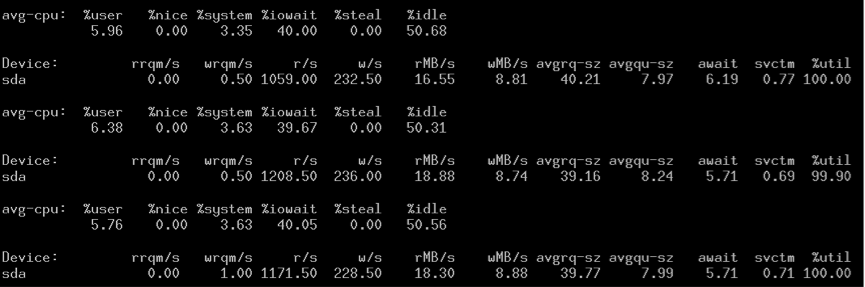
iops很高,svctm很小。
- 性能差的时候:
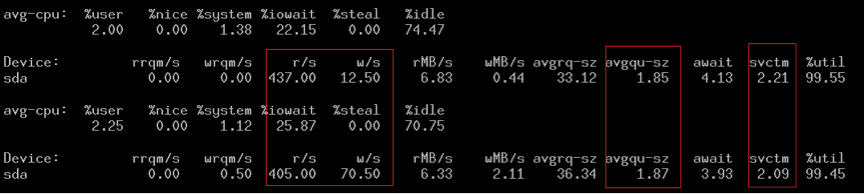
可以看到iops很低,svctm很长,但是IO队列avgqu-sz却很小,这说明上层(XFS)v 发送IO请求太慢,几乎是串行。 但是都是用的同样的压测方法,MySQL的配置都是一样的。难道是后者触发了XFS的某个条件,导致XFS变成了buffered IO?
尝试把OS的cache清除:
#echo 1 > /proc/sys/vm/drop_caches
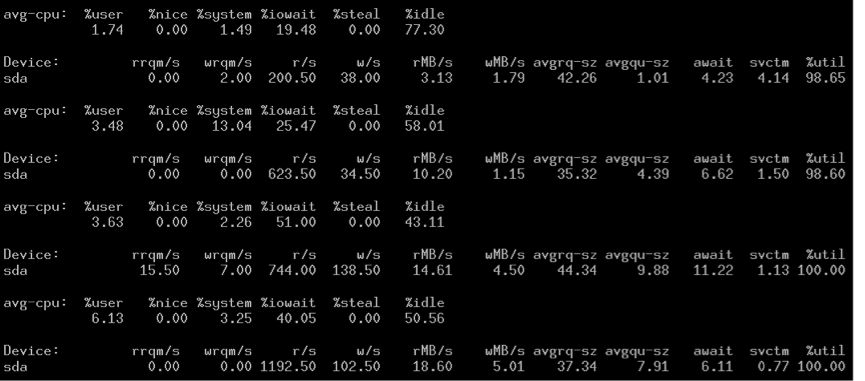
iops马上从200上升到1000+,这说明XFS与page cache有某种关系。
2 trace kernel
没办法,只能trace kernel。
#mount -t debug none /sys/kernel/debug
清除page cache的瞬间,mysql调用write的次数明显增加:
#./funccount -i 1 'xfs_file*'
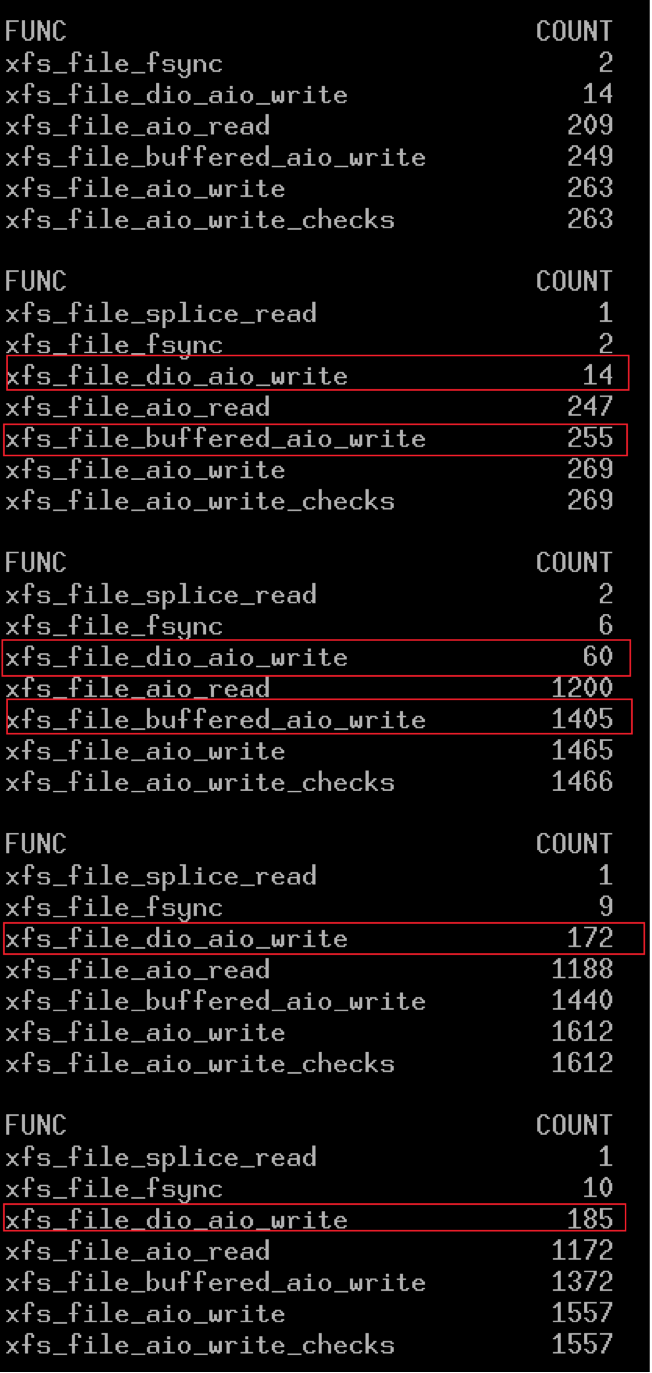
虽然使用了diret IO,但还是有很多buffered IO(xfs_file_buffered_aio_write),这可能来自binlog和redo log,为了便于分析,将binlog和redo log移到ext3分区。
为了便于分析,进行只读测试:
# ./funccount -i 1 "xfs_f*"
Tracing "xfs_f*"... Ctrl-C to end.
FUNC COUNT
xfs_file_aio_read 15591
xfs_flushinval_pages 15591
xfs_find_bdev_for_inode 31182
----------------echo 1 > /proc/sys/vm/drop_caches
FUNC COUNT
xfs_file_aio_read 15816
xfs_find_bdev_for_inode 31632
发现性能异常的时候,会调用xfs_flushinval_pages:
STATIC ssize_t
xfs_file_aio_read(
struct kiocb *iocb,
const struct iovec *iovp,
unsigned long nr_segs,
loff_t pos)
{
...
xfs_rw_ilock(ip, XFS_IOLOCK_SHARED);
if ((ioflags & IO_ISDIRECT) && inode->i_mapping->nrpages) {
xfs_rw_iunlock(ip, XFS_IOLOCK_SHARED);
xfs_rw_ilock(ip, XFS_IOLOCK_EXCL);
if (inode->i_mapping->nrpages) {
ret = -xfs_flushinval_pages(ip,
(iocb->ki_pos & PAGE_CACHE_MASK),
-1, FI_REMAPF_LOCKED);
if (ret) {
xfs_rw_iunlock(ip, XFS_IOLOCK_EXCL);
return ret;
}
}
xfs_rw_ilock_demote(ip, XFS_IOLOCK_EXCL);
}
...
调用xfs_flushinval_pages的时候,会使用EXCL锁,找到了性能差的直接原因了。
那么问题来了,inode->i_mapping->nrpages为什么会大于0呢?我使用了direct IO。文件的page cache是在什么时候产生的呢?
而且xfs_file_aio_read每次都会调用xfs_flushinval_pages。而后者每次都会删除文件的page cache。难道xfs_file_aio_read会产生page cache?
int
xfs_flushinval_pages(
xfs_inode_t *ip,
xfs_off_t first,
xfs_off_t last,
int fiopt)
{
struct address_space *mapping = VFS_I(ip)->i_mapping;
int ret = 0;
trace_xfs_pagecache_inval(ip, first, last);
xfs_iflags_clear(ip, XFS_ITRUNCATED);
ret = filemap_write_and_wait_range(mapping, first,
last == -1 ? LLONG_MAX : last);
if (!ret)
truncate_inode_pages_range(mapping, first, last); //删除inode page cahce
return -ret;
}
尝试trace add_to_page_cache_locked (address_space->nrpages++),发现该函数并没有被调用。难道xfs_flushinval_pages没有释放文件的page cache?
# ./funccount -i 1 "truncate_inode_page*"
Tracing "truncate_inode_page*"... Ctrl-C to end.
FUNC COUNT
truncate_inode_page 4
truncate_inode_pages 176
truncate_inode_pages_range 15474
FUNC COUNT
truncate_inode_page 1
truncate_inode_pages 5
truncate_inode_pages_range 15566
可以看到,truncate_inode_pages_range并没有调用truncate_inode_page,这说明文件的page cache并没有释放。
# ./funcgraph truncate_inode_pages_range
Tracing "truncate_inode_pages_range"... Ctrl-C to end.
2) 1.020 us | finish_task_switch();
2) | truncate_inode_pages_range() {
2) | pagevec_lookup() {
2) 0.413 us | find_get_pages();
2) 1.033 us | }
2) 0.238 us | _cond_resched();
2) | pagevec_lookup() {
2) 0.234 us | find_get_pages();
2) 0.690 us | }
2) 3.362 us | }
经过确认,truncate_inode_pages_range的确没有调用truncate_inode_page。这解释了xfs_file_aio_read为什么每次都会调用xfs_flushinval_pages。
那么问题又来了,truncate_inode_pages_range为什么不调用truncate_inode_page?
3测试程序
为此,写一个程序模拟MySQL的过程:
[pid 13478] open("./test/big_tb.ibd", O_RDONLY) = 37
[pid 13478] pread(37, "W\346\203@\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\v\37c\225\263\0\10\0\0\0\0\0\0"..., 16384, 0) = 16384
[pid 13478] close(37) = 0
[pid 13478] open("./test/big_tb.ibd", O_RDWR) = 37
[pid 13478] fcntl(37, F_SETFL, O_RDONLY|O_DIRECT) = 0
[pid 13478] fcntl(37, F_SETLK, {type=F_WRLCK, whence=SEEK_SET, start=0, len=0}) = 0
[pid 13478] pread(37, "\350\301\270\271\0\0\0\3\377\377\377\377\377\377\377\377\0\0\0\v\37c\225\263E\277\0\0\0\0\0\0"..., 16384, 49152) = 16384
[pid 13478] pread(37, "e\251|m\0\0\0\1\0\0\0\0\0\0\0\0\0\0\0\0\0\31\245\243\0\5\0\0\0\0\0\0"..., 16384, 16384) = 16384
可以看到InnoDB在打开一个表的时候,会两次打开数据文件,而第一次并没有使用direct IO,这解释了文件的page cache的产生原因。
到这里,我们还剩下一个问题:
** truncate_inode_pages_range为什么不调用truncate_inode_page? **
运行测试程序,基本过程如下:
open file without direct flag
read file //cause kernel readahead 4 pages, and inode->i_mapping->nrpages > 0
close file
open file with direct flag
read file //call xfs_flushinval_pages
read file //will not call xfs_flushinval_pages
...
发现第2次read调用xfs_flushinval_pages时,会调用truncate_inode_page,导致第3次的read并不会调用xfs_flushinval_pages。详细参考这里。
于是我将这个问题反馈给xfs开发者,参考这里
Dave Chinner的解释让我茅舍顿开,xfs_file_aio_read调用xfs_flushinval_pages时,是以iocb->ki_pos作为开始地址的。也就是如果MySQL后面一直不读取第0个page,那么MySQL第一次使用buffer read的page产生的page就一直得不到释放。
open file without direct flag
read file //cause kernel readahead 4 pages, and inode->i_mapping->nrpages > 0
close file
open file with direct flag
lseek 4*4096 // skip 4 readahead pages
read file //cause xfs_flushinval_pages to do nothing
read file //will call xfs_flushinval_pages
…
详细参考这里
4 总结
由于MySQL第一次的buffered IO,导致数据文件产生page cache,而且该page cache一直不会释放,导致后结的所有xfs_file_aio_read/xfs_file_dio_aio_write都会调用xfs_flushinval_pages,而且调用xfs_flushinval_pages的时候会使用EXCL锁,导致性能变差。
解决方法,MySQL层面可以将第一次open改成direct方式,这样就避免了后面的问题。那么XFS层面如何解决这一问题呢?XFS需要更加有效的flush条件,以inode->i_mapping->nrpages做为flush条件,太粗糙了。
PS,让我奇怪的是,网上看到很多人使用XFS跑MySQL,却没有看到人讨论这些问题,难道他们都没有遇到过这个问题么???
PS,Dave在回复我的邮件给我贴了一句Linux手册中的说明:
Applications should avoid mixing O_DIRECT and normal I/O to the same file, and especially to overlapping byte regions in the same file. Even when the filesystem correctly handles the coherency issues in this situation, overall I/O throughput is likely to be slower than using either mode alone. Likewise, applications should avoid mixing mmap(2) of files with direct I/O to the same files.
参考这里。
同时,他也指出了应用层如何解决这个问题:
Applications that need to mix buffered and direct IO can invalidate the cached pages by using POSIX_FADV_DONTNEED before doing direct IO.
5 附程序
/* gcc -o test_read test_read.c
* dd if=/dev/zero of=/data1/fo.dat bs=4096 count=10
* ./test_read /data1/fo.dat 2 direct
* */
#define _GNU_SOURCE
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
#include <stdlib.h>
#define BUFSIZE 4096
int read_count = 2;
int main(int argc, char *argv[]){
if(argc < 3){
fprintf(stderr, "usage: %s <file> <count> [buffer|direct]\n", argv[0]);
exit(1);
}
char *buf = memalign(BUFSIZE , BUFSIZE);
char *file = argv[1];
read_count = atoi(argv[2]);
int ret = 0,sum = 0, i = 0, fd = -1;
if(argc == 4 && strncmp(argv[3], "direct",6) == 0){
//fd = open(file, O_RDONLY|O_DIRECT);
fd = open(file, O_RDONLY);
if(fd < 0){
fprintf(stderr, "open read only file failed\n");
exit(1);
}
ret = read(fd, buf, BUFSIZE);
if(ret < 0){
fprintf(stderr, "buffer read error\n");
}
close(fd);
fd = open(file, O_RDWR);
if(fd < 0){
fprintf(stderr, "open read only file failed\n");
exit(1);
}
if (fcntl(fd, F_SETFL, O_RDONLY|O_DIRECT) == -1) {
fprintf(stderr, "set direct error\n");
exit(1);
}
}else{
fd = open(file, O_RDONLY);
if(fd < 0){
fprintf(stderr, "open buf file failed\n");
exit(1);
}
}
while(i++ < read_count){
//memset(buf, 0, BUFSIZE);
if(buf == NULL){
fprintf(stderr, "memory allocate failed\n");
exit(1);
}
if(lseek(fd, 0, SEEK_SET) < 0){
fprintf(stderr, "seek error!\n");
break;
}
ret = read(fd, buf, BUFSIZE);
if(ret > 0){
sum += ret;
}else if(ret == 0){
printf("read end\n");
break;
}
else{
printf("error:%d\n", errno);
break;
}
sleep(1);
}
printf("read sum: %d\n", sum);
close(fd);
free(buf);
return 0;
}
主要参考
http://lwn.net/Articles/341899/