1 概念
Goroutine的实现中有一些简单的概念。
M:对应一个OS线程,执行goroutine封装成的任务(这个任务有自己的代码逻辑、栈、程序计数器)
G:对应一个goroutine,相当于一个个的任务
P:调度器,维护调度上下文信息(context)和任务(goroutine)的运行队列(runqueues),并交给M执行。更确切的说,是M从调度器取任务执行。
M/G/P的关系:
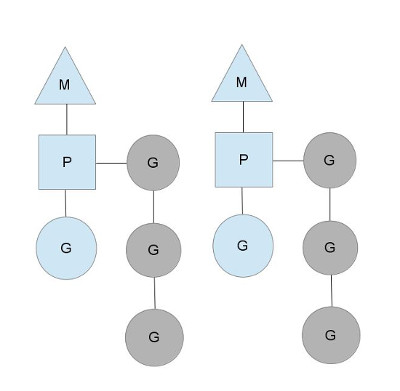
简单来说,goroutine的内部实现就是一个线程池。一般来说,有M和G就行了,这里为什么还要搞一个P?
这也是goroutine内部实现一个精妙的地方,当一个M执行G发生阻塞时(比如goroutine中有系统调用),可以将P转到别的M调度执行其它的G。
- struct G
go关键字创建一个goroutine,实际上会转化为runtime.newproc的调用:
go f(args)
可以看作
runtime.newproc(size, f, args)
runtime.newproc会创建一个G对象:
struct G
{
// stackguard0 can be set to StackPreempt as opposed to stackguard
uintptr stackguard0; // cannot move - also known to linker, libmach, runtime/cgo
uintptr stackbase; // cannot move - also known to libmach, runtime/cgo
Gobuf sched; ///PC, SP
uintptr stackguard; // same as stackguard0, but not set to StackPreempt
uintptr stack0;
uintptr stacksize;
int16 status; ///状态
uintptr gopc; // pc of go statement that created this goroutine
}
Goroutine的栈结构:
stack0 stackguard (stackguard0) stackbase
+---------------+-------------------------------------+---------------+
| StackGuard | STACK | Stktop |
+---------------+-------------------------------------+---------------+
low <--------------------------------------- SP high
每个goroutine都需要有一个自己的栈,G结构的sched字段维护了栈地址以及程序计数器等代码运行所需的基本信息。也就是说这个goroutine放弃cpu的时候需要保存这些信息,待下次重新获得cpu的时候,需要将这些信息装载到对应的cpu寄存器中。
函数到G的转换:
struct Gobuf
{
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
uintptr sp;
uintptr pc;
G* g;
void* ctxt;
uintreg ret;
uintptr lr;
};
// adjust Gobuf as it if executed a call to fn with context ctxt
// and then did an immediate gosave.
void
runtime·gostartcall(Gobuf *gobuf, void (*fn)(void), void *ctxt)
{
uintptr *sp;
sp = (uintptr*)gobuf->sp;
if(sizeof(uintreg) > sizeof(uintptr))
*--sp = 0;
*--sp = (uintptr)gobuf->pc;
gobuf->sp = (uintptr)sp;
gobuf->pc = (uintptr)fn;
gobuf->ctxt = ctxt;
}
- struct M
struct M
{
G* g0; // goroutine with scheduling stack,用于专门执行调度的逻辑
void (*mstartfn)(void); ///M对应的OS线程运行时,会先执行该回调函数
G* curg; // current running goroutine,当前运行的G
// 关联的P
P* p; // attached P for executing Go code (nil if not executing Go code)
MCache* mcache; ///用于M进行内存分配,参考内存管理
}
- struct P
struct P
{
M* m; // back-link to associated M (nil if idle)
// Queue of runnable goroutines.
uint32 runqhead; ///G队列
uint32 runqtail;
G* runq[256];
}
2 主要逻辑
2.1 创建G
runtime·newproc创建一个G,然后放到P的运行队列。
void
runtime·newproc(int32 siz, FuncVal* fn, ...)
{
byte *argp;
if(thechar == '5')
argp = (byte*)(&fn+2); // skip caller's saved LR
else
argp = (byte*)(&fn+1);
runtime·newproc1(fn, argp, siz, 0, runtime·getcallerpc(&siz));
}
G*
runtime·newproc1(FuncVal *fn, byte *argp, int32 narg, int32 nret, void *callerpc)
{
/// get G
...
p = m->p;
if((newg = gfget(p)) != nil) {
if(newg->stackguard - StackGuard != newg->stack0)
runtime·throw("invalid stack in newg");
} else {
newg = runtime·malg(StackMin);
allgadd(newg);
}
...
///设置相关字段
newg->sched.sp = (uintptr)sp;
newg->sched.pc = (uintptr)runtime·goexit;
newg->sched.g = newg;
runtime·gostartcallfn(&newg->sched, fn);
newg->gopc = (uintptr)callerpc;
newg->status = Grunnable;
...
///Try to put g on local runnable queue
runqput(p, newg); ///将G加入P的运行队列
///如果有空闲的P,而且没有自旋等待的M,则唤醒M来运行G
if(runtime·atomicload(&runtime·sched.npidle) != 0 && runtime·atomicload(&runtime·sched.nmspinning) == 0 && fn->fn != runtime·main) // TODO: fast atomic
wakep();
m->locks--;
if(m->locks == 0 && g->preempt) // restore the preemption request in case we've cleared it in newstack
g->stackguard0 = StackPreempt;
return newg;
}
...
// Tries to add one more P to execute G's.
// Called when a G is made runnable (newproc, ready).
static void
wakep(void)
{
// be conservative about spinning threads
if(!runtime·cas(&runtime·sched.nmspinning, 0, 1))
return;
startm(nil, true);
}
2.2 创建M
从OS层面来看,每个G代表的goroutine都需要一个M来运行。每个M都需要关联一个P,并从P的运行队列取出G运行;当M需要阻塞或者放弃运行时,会解除与P的关联,从而使得其它M能够关联并处理P的运行队列。所以,P的数量限制了同时运行的M的数量。
wakep会唤醒空闲的M处理空闲的P,如果没有可用的M,则创建新的M:
// Schedules some M to run the p (creates an M if necessary).
// If p==nil, tries to get an idle P, if no idle P's does nothing.
static void
startm(P *p, bool spinning)
{
M *mp;
void (*fn)(void);
runtime·lock(&runtime·sched);
if(p == nil) {
p = pidleget(); ///空闲的P
if(p == nil) {
runtime·unlock(&runtime·sched);
if(spinning)
runtime·xadd(&runtime·sched.nmspinning, -1);
return;
}
}
mp = mget(); ///获取一个空闲的M
runtime·unlock(&runtime·sched);
if(mp == nil) { ///没有可用的M,则创建M
fn = nil;
if(spinning)
fn = mspinning;
newm(fn, p); ///创建M
return;
}
从runtime来看,创建一个M,就是创建一个OS线程,这个线程从其关联的P取G并运行:
// Create a new m. It will start off with a call to fn, or else the scheduler.
static void
newm(void(*fn)(void), P *p){
M *mp;
mp = runtime·allocm(p);
mp->nextp = p;
mp->mstartfn = fn; ///runtime·mstart会调用该函数
...
runtime·newosproc(mp, (byte*)mp->g0->stackbase);
}
//os_linux.c
void
runtime·newosproc(M *mp, void *stk)
{
int32 ret;
int32 flags;
Sigset oset;
/*
* note: strace gets confused if we use CLONE_PTRACE here.
*/
flags = CLONE_VM /* share memory */
| CLONE_FS /* share cwd, etc */
| CLONE_FILES /* share fd table */
| CLONE_SIGHAND /* share sig handler table */
| CLONE_THREAD /* revisit - okay for now */
;
mp->tls[0] = mp->id; // so 386 asm can find it
// Disable signals during clone, so that the new thread starts
// with signals disabled. It will enable them in minit.
runtime·rtsigprocmask(SIG_SETMASK, &sigset_all, &oset, sizeof oset);
ret = runtime·clone(flags, stk, mp, mp->g0, runtime·mstart); ///执行runtime·mstart
runtime·rtsigprocmask(SIG_SETMASK, &oset, nil, sizeof oset);
}
可以看到,OS线程实际上是执行的runtime·mstart函数:
// Called to start an M.
void
runtime·mstart(void)
{
// Install signal handlers; after minit so that minit can
// prepare the thread to be able to handle the signals.
if(m == &runtime·m0)
runtime·initsig();
if(m->mstartfn)
m->mstartfn();
if(m->helpgc) {
m->helpgc = 0;
stopm();
} else if(m != &runtime·m0) {
acquirep(m->nextp);
m->nextp = nil;
}
schedule(); ///调度
}
schedule()进行任务(goroutine)调度。
2.3 调度G(运行M)
调度G是由M执行的,详细设计参考Scalable Go Scheduler Design Doc。
(1)先尝试从全局队列获取可运行的G;(2)没有G,则再尝试从关联的P的队列取G;(3)最后再尝试从其它队列获取G:
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
static void
schedule(void)
{
G *gp;
uint32 tick;
...
// by constantly respawning each other.
tick = m->p->schedtick;
// This is a fancy way to say tick%61==0,
// it uses 2 MUL instructions instead of a single DIV and so is faster on modern processors.
if(tick - (((uint64)tick*0x4325c53fu)>>36)*61 == 0 && runtime·sched.runqsize > 0) {
runtime·lock(&runtime·sched);
gp = globrunqget(m->p, 1);
runtime·unlock(&runtime·sched);
if(gp)
resetspinning();
}
if(gp == nil) {
gp = runqget(m->p);///从关联的P取一个G
if(gp && m->spinning)
runtime·throw("schedule: spinning with local work");
}
if(gp == nil) { ///从其它队列取G
gp = findrunnable(); // blocks until work is available
resetspinning();
}
...
execute(gp); ///运行G
}
- work stealing
当M关联的P没有可运行的G时,就会从其它的队列移动一些G到当前的P,这就是所谓的work-stealing算法。runtime的work stealing算法是在函数findrunnable实现的。
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from global queue, poll network.
static G*
findrunnable(void)
{
///...
// random steal from other P's
for(i = 0; i < 2*runtime·gomaxprocs; i++) {
if(runtime·sched.gcwaiting)
goto top;
p = runtime·allp[runtime·fastrand1()%runtime·gomaxprocs];
if(p == m->p)
gp = runqget(p);
else
gp = runqsteal(m->p, p); ///从P'偷'一半放到m->p
if(gp)
return gp;
}
///...
}
2.4 运行G
// Schedules gp to run on the current M.
// Never returns.
static void
execute(G *gp)
{
int32 hz;
if(gp->status != Grunnable) {
runtime·printf("execute: bad g status %d\n", gp->status);
runtime·throw("execute: bad g status");
}
gp->status = Grunning;
gp->waitsince = 0;
gp->preempt = false;
gp->stackguard0 = gp->stackguard;
m->p->schedtick++;
m->curg = gp;
gp->m = m;
// Check whether the profiler needs to be turned on or off.
hz = runtime·sched.profilehz;
if(m->profilehz != hz)
runtime·resetcpuprofiler(hz);
runtime·gogo(&gp->sched);
}
///asm_amd64.s
// void gogo(Gobuf*)
// restore state from Gobuf; longjmp
TEXT runtime·gogo(SB), NOSPLIT, $0-8
MOVQ 8(SP), BX // gobuf
MOVQ gobuf_g(BX), DX
MOVQ 0(DX), CX // make sure g != nil
get_tls(CX)
MOVQ DX, g(CX)
MOVQ gobuf_sp(BX), SP // restore SP
MOVQ gobuf_ret(BX), AX
MOVQ gobuf_ctxt(BX), DX
MOVQ $0, gobuf_sp(BX) // clear to help garbage collector
MOVQ $0, gobuf_ret(BX)
MOVQ $0, gobuf_ctxt(BX)
MOVQ gobuf_pc(BX), BX
JMP BX
3 调度时机
3.1 goroutine结束
- runtime·goexit
很显然,当G运行结束时,都会调用runtime·goexit做一些清理工作,后者会调用schedule运行一个新的G:
void
runtime·goexit(void)
{
if(g->status != Grunning)
runtime·throw("bad g status");
if(raceenabled)
runtime·racegoend();
runtime·mcall(goexit0);
}
// runtime·goexit continuation on g0.
static void
goexit0(G *gp)
{
...
schedule();
}
- runtime·mcall
注意,runtime·goexit通过runtime·mcall调用goexit0,runtime·mcall会切到m->g0的栈,因为goexit0的逻辑不属于某个G,每个M都有一个g0,它的栈专门用于执行调度的逻辑。详细参考runtime/asm_amd64.s文件。
// void mcall(void (*fn)(G*))
// Switch to m->g0's stack, call fn(g).
// Fn must never return. It should gogo(&g->sched)
// to keep running g.
TEXT runtime·mcall(SB), NOSPLIT, $0-8
MOVQ fn+0(FP), DI
get_tls(CX)
MOVQ g(CX), AX // save state in g->sched
MOVQ 0(SP), BX // caller's PC
MOVQ BX, (g_sched+gobuf_pc)(AX)
LEAQ 8(SP), BX // caller's SP
MOVQ BX, (g_sched+gobuf_sp)(AX)
MOVQ AX, (g_sched+gobuf_g)(AX)
// switch to m->g0 & its stack, call fn
MOVQ m(CX), BX
MOVQ m_g0(BX), SI
CMPQ SI, AX // if g == m->g0 call badmcall
JNE 3(PC)
MOVQ $runtime·badmcall(SB), AX
JMP AX
MOVQ SI, g(CX) // g = m->g0
MOVQ (g_sched+gobuf_sp)(SI), SP // sp = m->g0->sched.sp
PUSHQ AX // g -> SP
ARGSIZE(8)
CALL DI // call fn
POPQ AX
MOVQ $runtime·badmcall2(SB), AX
JMP AX
RET
3.2 runtime·park
goroutine可以执行runtime·park挂起自己,M会运行一个新的G:
// Puts the current goroutine into a waiting state and calls unlockf.
// If unlockf returns false, the goroutine is resumed.
void
runtime·park(bool(*unlockf)(G*, void*), void *lock, int8 *reason)
{
if(g->status != Grunning)
runtime·throw("bad g status");
m->waitlock = lock;
m->waitunlockf = unlockf;
g->waitreason = reason;
runtime·mcall(park0);
}
// runtime·park continuation on g0.
static void
park0(G *gp)
{
bool ok;
gp->status = Gwaiting;
gp->m = nil;
m->curg = nil;
if(m->waitunlockf) {
ok = m->waitunlockf(gp, m->waitlock);
m->waitunlockf = nil;
m->waitlock = nil;
if(!ok) {
gp->status = Grunnable;
execute(gp); // Schedule it back, never returns.
}
}
if(m->lockedg) {
stoplockedm();
execute(gp); // Never returns.
}
schedule(); ///调度
}
- runtime·ready
对于调用runtime·park陷入阻塞的G,只有调用runtime·ready函数才能唤醒。
// Mark gp ready to run.
void
runtime·ready(G *gp)
{
// Mark runnable.
m->locks++; // disable preemption because it can be holding p in a local var
if(gp->status != Gwaiting) {
runtime·printf("goroutine %D has status %d\n", gp->goid, gp->status);
runtime·throw("bad g->status in ready");
}
gp->status = Grunnable;
/// put g on local runnable queue
runqput(m->p, gp);
if(runtime·atomicload(&runtime·sched.npidle) != 0 && runtime·atomicload(&runtime·sched.nmspinning) == 0) // TODO: fast atomic
wakep();
m->locks--;
if(m->locks == 0 && g->preempt) // restore the preemption request in case we've cleared it in newstack
g->stackguard0 = StackPreempt;
}
值得注意的是,runtime·park和runtime·ready在channel的实现中用到。
3.3 runtime·gosched
可以调用runtime.Goshed()主动放弃CPU。注意gosched与park的区别,前者的G为Grunnable状态,而且放在全局调度队列:
// Scheduler yield.
void
runtime·gosched(void)
{
if(g->status != Grunning)
runtime·throw("bad g status");
runtime·mcall(runtime·gosched0);
}
// runtime·gosched continuation on g0.
void
runtime·gosched0(G *gp)
{
gp->status = Grunnable;
gp->m = nil;
m->curg = nil;
runtime·lock(&runtime·sched);
globrunqput(gp);
runtime·unlock(&runtime·sched);
if(m->lockedg) {
stoplockedm();
execute(gp); // Never returns.
}
schedule();
}
3.4 系统调用
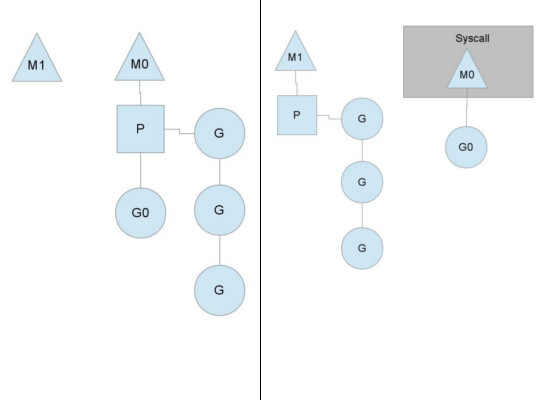
Go语言自身对系统调用进行了封装(syscall/zsyscall_linux_amd64.go)。当goroutine执行系统调用时,对应的M(OS线程)会陷入阻塞状态,不能运行其它的G。此时,需要将P转给其它M调度。
系统调用封装:
// syscall/asm_linux_amd64.s
// System calls for AMD64, Linux
//
// func Syscall(trap int64, a1, a2, a3 int64) (r1, r2, err int64);
// Trap # in AX, args in DI SI DX R10 R8 R9, return in AX DX
// Note that this differs from "standard" ABI convention, which
// would pass 4th arg in CX, not R10.
TEXT ·Syscall(SB),NOSPLIT,$0-56
CALL runtime·entersyscall(SB)
MOVQ 16(SP), DI
MOVQ 24(SP), SI
MOVQ 32(SP), DX
MOVQ $0, R10
MOVQ $0, R8
MOVQ $0, R9
MOVQ 8(SP), AX // syscall entry
SYSCALL
CMPQ AX, $0xfffffffffffff001
JLS ok
MOVQ $-1, 40(SP) // r1
MOVQ $0, 48(SP) // r2
NEGQ AX
MOVQ AX, 56(SP) // errno
CALL runtime·exitsyscall(SB)
RET
ok:
MOVQ AX, 40(SP) // r1
MOVQ DX, 48(SP) // r2
MOVQ $0, 56(SP) // errno
CALL runtime·exitsyscall(SB)
RET
可以看到,在执行系统调用之前,会调用runtime·entersyscall,返回的时候,会调用runtime·exitsyscall。
runtime·entersyscall不会主动释放P,但sysmon会处理长时间处于Psyscall状态的P。runtime·entersyscallblock会主动释放P。
void
·entersyscall(int32 dummy)
{
runtime·reentersyscall(runtime·getcallerpc(&dummy), runtime·getcallersp(&dummy));
}
void
·entersyscallblock(int32 dummy)
{
P *p;
m->locks++; // see comment in entersyscall
///保存G的现场
// Leave SP around for GC and traceback.
save(runtime·getcallerpc(&dummy), runtime·getcallersp(&dummy));
g->syscallsp = g->sched.sp;
g->syscallpc = g->sched.pc;
g->syscallstack = g->stackbase;
g->syscallguard = g->stackguard;
g->status = Gsyscall;
if(g->syscallsp < g->syscallguard-StackGuard || g->syscallstack < g->syscallsp) {
// runtime·printf("entersyscall inconsistent %p [%p,%p]\n",
// g->syscallsp, g->syscallguard-StackGuard, g->syscallstack);
runtime·throw("entersyscallblock");
}
///释放P
p = releasep();
handoffp(p); ///转给别的M
if(g->isbackground) // do not consider blocked scavenger for deadlock detection
incidlelocked(1);
// Resave for traceback during blocked call.
save(runtime·getcallerpc(&dummy), runtime·getcallersp(&dummy));
g->stackguard0 = StackPreempt; // see comment in entersyscall
m->locks--;
}
4 sysmon goroutine
sysmon有3个作用:(1)将长时间没有处理的netpoll的G添加全局队列;(2)处理长时间处于Psyscall状态的P;(3)设置过长时间运行的G的抢占标志位。
// The main goroutine.
void
runtime·main(void)
{
...
newm(sysmon, nil); ///sysmon goroutine
...
}
static void
sysmon(void)
{
uint32 idle, delay;
int64 now, lastpoll, lasttrace;
G *gp;
lasttrace = 0;
idle = 0; // how many cycles in succession we had not wokeup somebody
delay = 0;
for(;;) {
...
// retake P's blocked in syscalls
// and preempt long running G's
if(retake(now))
idle = 0;
else
idle++;
...
}
5 LockOSThread
因为goroutine和OS线程并不是一一对应的关系。在一些场景下,我们希望goroutine在同一个OS线程中运行,比如goroutine使用了线程局部存储,LockOSThread能够保证goroutine在同一个OS线程中运行:
LockOSThread wires the calling goroutine to its current operating system thread. Until the calling goroutine exits or calls UnlockOSThread, it will always execute in that thread, and no other goroutine can.
struct G
{
...
M* lockedm;
...
}
struct M
{
...
uint32 locked; // tracking for LockOSThread
G* lockedg;
...
}
// lockOSThread is called by runtime.LockOSThread and runtime.lockOSThread below
// after they modify m->locked. Do not allow preemption during this call,
// or else the m might be different in this function than in the caller.
#pragma textflag NOSPLIT
static void
lockOSThread(void)
{
m->lockedg = g;
g->lockedm = m;
}
void
runtime·LockOSThread(void)
{
m->locked |= LockExternal;
lockOSThread();
}
void
runtime·lockOSThread(void)
{
m->locked += LockInternal;
lockOSThread();
}
在调度G的时候,如果发现G->lockedm被设置,则会将G(实际上是关联的P)转给对应的M:
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
static void
schedule(void)
{
...
if(gp->lockedm) {
// Hands off own p to the locked m,
// then blocks waiting for a new p.
startlockedm(gp);
goto top;
}
...
}
// Schedules the locked m to run the locked gp.
static void
startlockedm(G *gp)
{
M *mp;
P *p;
//锁定的M
mp = gp->lockedm;
if(mp == m)
runtime·throw("startlockedm: locked to me");
if(mp->nextp)
runtime·throw("startlockedm: m has p");
// directly handoff current P to the locked m
incidlelocked(-1);
//当前M与P解除绑定
p = releasep();
//目标M与P绑定
mp->nextp = p;
//wakeup目标M
runtime·notewakeup(&mp->park);
//休眠当前M
stopm();
}
当goroutine结束时,会解除M和G的这种锁定关系:
// runtime·goexit continuation on g0.
static void
goexit0(G *gp)
{
gp->lockedm = nil;
m->lockedg = nil;
m->locked = 0;
...
}
考虑如下程序:
func main{
var wg sync.WaitGroup
wg.Add(1)
go func(){
defer wg.Done()
runtime.LockOSThread()
// sleep
time.Sleep(10 * time.Second)
}()
wg.Wait()
}
当主goroutine G0对应的M创建一个G1,并放到M->P的运行队列。G0等待,执行G1中的runtime.LockOSThread,G1被挂起。如果此时,M有锁定的G(G1),M不会调度新的G运行,而将P转给别的M,然后陷入休眠状态。唤醒后重新执行G1。
// runtime·park continuation on g0.
static void
park0(G *gp)
{
bool ok;
gp->status = Gwaiting;
gp->m = nil;
m->curg = nil;
...
/// 有锁定的G
if(m->lockedg) {
stoplockedm(); ///休眠当前M
execute(gp); // Never returns.
}
schedule();
}
// Stops execution of the current m that is locked to a g until the g is runnable again.
// Returns with acquired P.
static void
stoplockedm(void)
{
P *p;
///将P转到其它M
if(m->p) {
// Schedule another M to run this p.
p = releasep();
handoffp(p);
}
incidlelocked(1);
/// 陷入休眠
// Wait until another thread schedules lockedg again.
runtime·notesleep(&m->park);
runtime·noteclear(&m->park);
if(m->lockedg->status != Grunnable)
runtime·throw("stoplockedm: not runnable");
acquirep(m->nextp);
m->nextp = nil;
}
从上面的分析可以看到,当goroutine执行runtime.LockOSThread后,该goroutine只会在锁定的M执行,同时,M也只会执行锁定的G,直到锁定的G执行结束。由于go语言中,goroutine与OS线程不是一一对应的,我们必须小心处理一些依赖于底层OS线程的场景,比如线程局部存储,再比如net namespace,而runtime.LockOSThread保证了goroutine与OS线程的一一对应。
6 其它
6.1 time.Sleep
调用time.Sleep后,会让当前goroutine挂起,详细参考这里。
// runtime/time.goc
// Sleep puts the current goroutine to sleep for at least ns nanoseconds.
func Sleep(ns int64) {
runtime·tsleep(ns, "sleep");
}
// Put the current goroutine to sleep for ns nanoseconds.
void
runtime·tsleep(int64 ns, int8 *reason)
{
Timer t;
if(ns <= 0)
return;
t.when = runtime·nanotime() + ns;
t.period = 0;
t.fv = &readyv;
t.arg.data = g;
runtime·lock(&timers);
addtimer(&t);
runtime·parkunlock(&timers, reason);
}
6.2 GOMAXPROCS
GOMAXPROCS可以限制OS层面同时运行M的数量(注意并不能限制创建M的数量,M可能因为执行系统调用发生阻塞,这时runtime会创建新的M),默认值(Go1.3)为1,最大256。
The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go
code simultaneously. There is no limit to the number of threads that can be blocked in system calls
on behalf of Go code; those do not count against the GOMAXPROCS limit. This package's GOMAXPROCS
function queries and changes the limit.
实际上,从runtime来看,GOMAXPROCS限制了P的数量:
void
runtime·schedinit(void)
{
///...
procs = 1;
p = runtime·getenv("GOMAXPROCS");
if(p != nil && (n = runtime·atoi(p)) > 0) {
if(n > MaxGomaxprocs) ///最多256个P
n = MaxGomaxprocs;
procs = n;
}
runtime·allp = runtime·malloc((MaxGomaxprocs+1)*sizeof(runtime·allp[0]));///创建P
procresize(procs);
从Go1.5开始,GOMAXPROCS默认设置为CPU的核数。