Heartbeat Interval and Election Timeout
Heartbeat Interval
- (1)leader发送心跳(AppendEntriesRequest)
Leader向follower发送心跳的间隔时间,用于向follower表示leader状态正常,默认时间为50ms。Leader在发送心跳的时候,会发送log entry。
//--------------------------------------
// Heartbeat
//--------------------------------------
// Listens to the heartbeat timeout and flushes an AppendEntries RPC.
func (p *Peer) heartbeat(c chan bool) {
stopChan := p.stopChan
c <- true
ticker := time.Tick(p.heartbeatInterval) ///默认50 ms
debugln("peer.heartbeat: ", p.Name, p.heartbeatInterval)
for {
select {
case flush := <-stopChan:
if flush {
// before we can safely remove a node
// we must flush the remove command to the node first
p.flush()
debugln("peer.heartbeat.stop.with.flush: ", p.Name)
return
} else {
debugln("peer.heartbeat.stop: ", p.Name)
return
}
case <-ticker: ///发送心跳
start := time.Now()
p.flush()
duration := time.Now().Sub(start)
p.server.DispatchEvent(newEvent(HeartbeatEventType, duration, nil))
}
}
}
func (p *Peer) flush() {
debugln("peer.heartbeat.flush: ", p.Name)
prevLogIndex := p.getPrevLogIndex() ///end log index of last send
term := p.server.currentTerm ///current Term
entries, prevLogTerm := p.server.log.getEntriesAfter(prevLogIndex, p.server.maxLogEntriesPerRequest)
if entries != nil { ///send log entry
p.sendAppendEntriesRequest(newAppendEntriesRequest(term, prevLogIndex, prevLogTerm, p.server.log.CommitIndex(), p.server.name, entries))
} else { ///no log entry mean log entries for this peer has compacted, peer shoud do snapshot and redo the log entry after snapshot
p.sendSnapshotRequest(newSnapshotRequest(p.server.name, p.server.snapshot))
}
}
很显然,对每个peer,leader都会启动一个goroutine来发送heartbeat:
func (s *server) leaderLoop() {
...
for _, peer := range s.peers {
peer.setPrevLogIndex(logIndex)
peer.startHeartbeat()
}
leader会记录给每个follower已经完成发送并且已经由follower确认的log entry的最新Index(p.getPrevLogIndex())。但是leader做快照的时候,会删除已经commit的log entry。
考虑一种情况,如果follower在某个点挂了,过了很长时间才恢复,当它重新加入集群时,leader对该follower节点尝试发送prevLogIndex之后的log entries,但由于这部分log entries已经可能删除。log.getEntriesAfter返回nil,那么follower应该如果追赶这部分丢失的log entries呢?
实际上,在这种情况下,leader会给follower发送一个SnapshotRequest,follower转入Snapshotting状态;然后leader再把snapshot数据发送给follower,follower从快照恢复数据;leader再从snapshot.LastIndex开始给该follower发送log entry。
### follower
[etcd] May 19 03:17:44.885 INFO | node1 starting in peer mode
[etcd] May 19 03:17:44.885 INFO | node1: state changed from 'initialized' to 'follower'.
[etcd] May 19 03:17:44.902 DEBUG | [recv] POST http://172.17.42.40:7001/snapshot
[etcd] May 19 03:17:44.902 INFO | node1: state changed from 'follower' to 'snapshotting'.
[etcd] May 19 03:17:44.908 DEBUG | [recv] POST http://172.17.42.40:7001/snapshotRecovery
** leader **
// Sends an Snapshot request to the peer through the transport.
func (p *Peer) sendSnapshotRequest(req *SnapshotRequest) {
///(0) send SnapshotRequest
resp := p.server.Transporter().SendSnapshotRequest(p.server, p, req)
// If successful, the peer should have been to snapshot state
// Send it the snapshot!
p.setLastActivity(time.Now())
if resp.Success {
p.sendSnapshotRecoveryRequest() /// (1) send snapshot data
} else {
debugln("peer.snap.failed: ", p.Name)
return
}
}
** follower **
1) follower -> Snapshotting
func (s *server) processSnapshotRequest(req *SnapshotRequest) *SnapshotResponse {
// If the follower’s log contains an entry at the snapshot’s last index with a term
// that matches the snapshot’s last term, then the follower already has all the
// information found in the snapshot and can reply false.
entry := s.log.getEntry(req.LastIndex)
if entry != nil && entry.Term() == req.LastTerm {
return newSnapshotResponse(false)
}
// Update state.
s.setState(Snapshotting) ///state change to Snapshotting
return newSnapshotResponse(true)
}
2) follower recovery snapshot
func (s *server) SnapshotRecoveryRequest(req *SnapshotRecoveryRequest) *SnapshotRecoveryResponse {
ret, _ := s.send(req)
resp, _ := ret.(*SnapshotRecoveryResponse)
return resp
}
- (2)follower接收心跳请求
follower收到leader发送的心跳消息后,主要做以下几件事件:
1)比较req.Term与self.currentTerm。
如果req.Term < self.currentTerm,意味着此时leader已经落后于follower,follower会返回失败给leader,
而且会将自己的[ currentTerm.currentIndex、log.commitIndex ] 返回给leader;
如果req.Term > self.currentTerm,follower会更新自己的currentTerm。
2)将log entry写到本地log file;
3)将req.CommitIndex之前所有log entry commit(即apply);
至此,req.CommitIndex之前的修改在leader和follower都已经落地;(注意本次接收的log entries并没有commit)
4)follower将自己的[ currentTerm.currentIndex、log.commitIndex ]信息返回给leader。
- (3)leader收到follower的心跳回复(AppendEntriesResponse)
leader再发送完心跳request后,会阻塞等待follower的response,如果没有收follower的response(超时),就会输出下面的信息:
etcd-node3: warning: heartbeat time out peer="etcd-node1" missed=1 backoff="2s"
表明follower失去联系(leader与follower的网络中断,或者follower挂掉)。
// Sends an AppendEntries request to the peer through the transport.
func (p *Peer) sendAppendEntriesRequest(req *AppendEntriesRequest) {
tracef("peer.append.send: %s->%s [prevLog:%v length: %v]\n",
p.server.Name(), p.Name, req.PrevLogIndex, len(req.Entries))
resp := p.server.Transporter().SendAppendEntriesRequest(p.server, p, req)
if resp == nil { ///(0) don't receive response from peer
p.server.DispatchEvent(newEvent(HeartbeatIntervalEventType, p, nil))
debugln("peer.append.timeout: ", p.server.Name(), "->", p.Name)
return
}
Election Timeout
follower如果在该时间内没有收到leader的heartbeat消息,follower就将自己变成condidate,发起新一轮选举,etcd默认为200ms。
// The event loop that is run when the server is in a Follower state.
// Responds to RPCs from candidates and leaders.
// Converts to candidate if election timeout elapses without either:
// 1.Receiving valid AppendEntries RPC, or
// 2.Granting vote to candidate
func (s *server) followerLoop() {
since := time.Now()
electionTimeout := s.ElectionTimeout()
///(0)等待[timout, 2*timeout]内的一个随机数
timeoutChan := afterBetween(s.ElectionTimeout(), s.ElectionTimeout()*2)
for s.State() == Follower {
case e := <-s.c:
...
update := false
select {
case *AppendEntriesRequest: ///(1) 收到leader的心跳
// If heartbeats get too close to the election timeout then send an event.
elapsedTime := time.Now().Sub(since)
if elapsedTime > time.Duration(float64(electionTimeout)*ElectionTimeoutThresholdPercent) {
///如果在超过0.8*timeout的时间内收到心跳,输出一条warning信息
s.DispatchEvent(newEvent(ElectionTimeoutThresholdEventType, elapsedTime, nil))
}
e.returnValue, update = s.processAppendEntriesRequest(req)
}
...
case <-timeoutChan: ///(2) electiontimeout, to be Candidate
// only allow synced follower to promote to candidate
if s.promotable() {
s.setState(Candidate)
} else {
update = true
}
}
///(3)重置等待时间
// Converts to candidate if election timeout elapses without either:
// 1.Receiving valid AppendEntries RPC, or
// 2.Granting vote to candidate
if update {
since = time.Now()
timeoutChan = afterBetween(s.ElectionTimeout(), s.ElectionTimeout()*2)
}
}
如果follower超过0.8 * electiontimout的时间才收到leader的心跳,就会输出下面的warning信息:
etcd-node2: warning: heartbeat near election timeout: 181.195585ms
etcd的两阶段提交
整体函数调用:
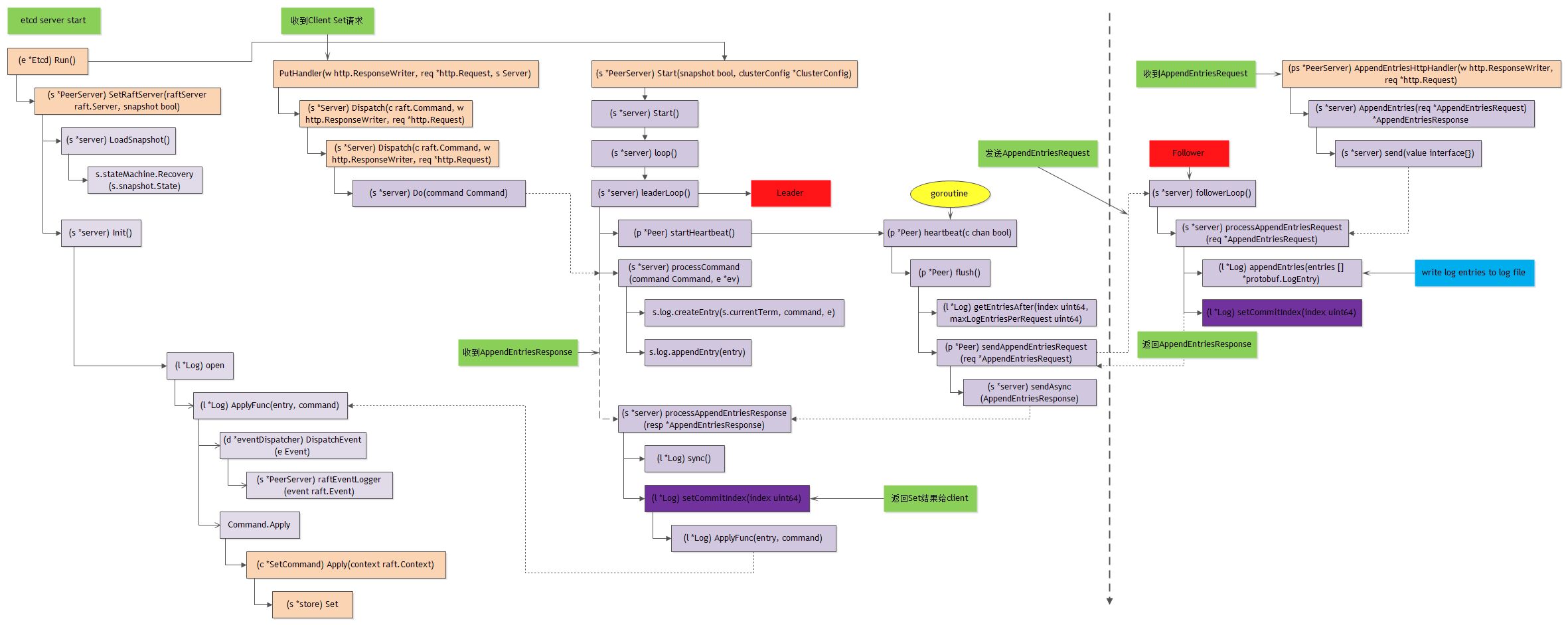
- 第一个阶段:
(1)leader收到client的更新(set)请求,leader将请求转成log entry记录到本地log file;
(2)在下一个心跳消息时,将log entry发送给follower;
(3)follower收到log entry后,将log entry写到本地log file(sync);并将leader的commitIndex之前的log entry commit,即修改内存对应的数据(注意并不是本次收到log entry);
(4)返回AppendEntriesResponse给leader;
- 第二阶段:
(1)如果收到多数follower完成log entry成功写到log file,就根据每个follower写入log file的log entry index计算出commitIndex;
这个commitIndex等于多数follower都完成写入的log entry的最大index。举个例子:
考虑5个节点:A为leader,B写入的log entry的最大index为10,C写入的log entry最大index为8,D为6,
E为4;那么commitIndex为6。因为index <=6的log entry在大多数的节点都完成了写入。
(2)将commitInde之前的log entry在leader commit(即修改内存对应的数据);
- 做commit一个log entry,就会相应增加log.commitIndex(已经完成commit的index);
- apply update
- 在log entry apply完成之后,会通知处理client request的请求的goroutine,给client返回更新请求的结果;
从这里也可以看到leader只有在收到更新操作在多数节点落地后,才会给client返回结果。
// Updates the commit index and writes entries after that index to the stable storage.
func (l *Log) setCommitIndex(index uint64) error {
...
// Find all entries whose index is between the previous index and the current index.
for i := l.commitIndex + 1; i <= index; i++ {
entryIndex := i - 1 - l.startIndex
entry := l.entries[entryIndex]
// Update commit index.
l.commitIndex = entry.Index() ///(0) update commit index
// Decode the command.
command, err := newCommand(entry.CommandName(), entry.Command())
if err != nil {
return err
}
// Apply the changes to the state machine and store the error code.
returnValue, err := l.ApplyFunc(entry, command) /// (1) apply update
if entry.event != nil { /// (3)notify server routine to retuern response to client
entry.event.returnValue = returnValue
entry.event.c <- err
}
对每一个client,(go server框架)都会生成一个(服务)goroutine处理请求,raft server只有在收到多数节点成功的response之后,才会返回:
// Sends an event to the event loop to be processed. The function will wait
// until the event is actually processed before returning.
func (s *server) send(value interface{}) (interface{}, error) {
if !s.Running() {
return nil, StopError
}
event := &ev{target: value, c: make(chan error, 1)}
select {
case s.c <- event: ///notify loop routine to process command
case <-s.stopped:
return nil, StopError
}
select {
case <-s.stopped:
return nil, StopError
case err := <-event.c: ///wait command result from loop routine, see setCommitIndex
return event.returnValue, err
}
}
(3)在下一个心跳,leader的log.commitIndex会随心跳一起发送给follower,follower再执行 commit操作。
- 问题
** Question 1: 如果集群的多数节点都挂掉,leader收到client请求会怎么样? **
Answer: 如果多数节点都挂掉,会导致etcd服务goroutine一直阻塞,从而也导致client一直阻塞,得不到结果。
值得注意的是在v0.4.6中,对GET操作,默认会从指定的节点读取结果(如果指定是follow节点,可能读取不到最新的数据);
如果client指定了consistent=true,flollower会将请求重定向到leader,但不会阻塞client;
如果指定了quorum=true,那么会像PUT一样,进行raft GET,此时,就会阻塞client。
func GetHandler(w http.ResponseWriter, req *http.Request, s Server) error {
vars := mux.Vars(req)
key := "/" + vars["key"]
recursive := (req.FormValue("recursive") == "true")
sort := (req.FormValue("sorted") == "true")
if req.FormValue("quorum") == "true" {
c := s.Store().CommandFactory().CreateGetCommand(key, recursive, sort)
return s.Dispatch(c, w, req) ///(0) raft READ
}
///(1) Help client to redirect the request to the current leader
if req.FormValue("consistent") == "true" && s.State() != raft.Leader {
leader := s.Leader()
hostname, _ := s.ClientURL(leader)
url, err := url.Parse(hostname)
if err != nil {
log.Warn("Redirect cannot parse hostName ", hostname)
return err
}
url.RawQuery = req.URL.RawQuery
url.Path = req.URL.Path
log.Debugf("Redirect consistent get to %s", url.String())
http.Redirect(w, req, url.String(), http.StatusTemporaryRedirect)
return nil
}
所以,consistent与quorum两个参数是有区别的,参考Read Consistency。
** Question 2: 如果log entry在发送给follower过程中丢掉,会怎么样? **
Answer: leader会保存对每个follower发送log entry的情况,包括follower已经收到并且appended的log entry index,log entry是否已经appended(写到log file)。下个心跳,会继续发送没有被follower appended的 log entry。
(1) peer信息
// A peer is a reference to another server involved in the consensus protocol.
type Peer struct {
server *server
Name string `json:"name"`
ConnectionString string `json:"connectionString"`
prevLogIndex uint64 ///appended entry index, entries tha to this value has sended to peer and appended by peer ///log entry has appended by peer
stopChan chan bool
heartbeatInterval time.Duration ///heartbeat interval
lastActivity time.Time
sync.RWMutex
}
(2) log entry的发送及appended index的更新
func (p *Peer) flush() {
debugln("peer.heartbeat.flush: ", p.Name)
prevLogIndex := p.getPrevLogIndex() ///end log index of last send
term := p.server.currentTerm ///current Term
///从已经appended的index开始,发送log entry
entries, prevLogTerm := p.server.log.getEntriesAfter(prevLogIndex, p.server.maxLogEntriesPerRequest)
if entries != nil { ///send log entry
p.sendAppendEntriesRequest(newAppendEntriesRequest(term, prevLogIndex, prevLogTerm, p.server.log.CommitIndex(), p.server.name, entries))
} else {
p.sendSnapshotRequest(newSnapshotRequest(p.server.name, p.server.snapshot))
}
}
//--------------------------------------
// Append Entries
//--------------------------------------
// Sends an AppendEntries request to the peer through the transport.
func (p *Peer) sendAppendEntriesRequest(req *AppendEntriesRequest) {
tracef("peer.append.send: %s->%s [prevLog:%v length: %v]\n",
p.server.Name(), p.Name, req.PrevLogIndex, len(req.Entries))
resp := p.server.Transporter().SendAppendEntriesRequest(p.server, p, req)
if resp == nil { ///(0) don't receive response from peer
p.server.DispatchEvent(newEvent(HeartbeatIntervalEventType, p, nil))
debugln("peer.append.timeout: ", p.server.Name(), "->", p.Name)
return
}
p.setLastActivity(time.Now())
// If successful then update the previous log index.
p.Lock()
if resp.Success() { ///(1) success
if len(req.Entries) > 0 {
p.prevLogIndex = req.Entries[len(req.Entries)-1].GetIndex() ///(2)更新index的值
// if peer append a log entry from the current term
// we set append to true
if req.Entries[len(req.Entries)-1].GetTerm() == p.server.currentTerm {
resp.append = true
}
}
snapshot
etcd每隔30s就会做一次snapshot:将内存的数据写到磁盘,然后删除commit Index之前的log entry:
func (s *PeerServer) monitorSnapshot() {
for {
timer := time.NewTimer(s.snapConf.checkingInterval) ///30s
select {
case <-s.closeChan:
timer.Stop()
return
case <-timer.C:
}
currentIndex := s.RaftServer().CommitIndex()
count := currentIndex - s.snapConf.lastIndex
if uint64(count) > s.snapConf.snapshotThr {
err := s.raftServer.TakeSnapshot() ///do snapshot
s.logSnapshot(err, currentIndex, count)
s.snapConf.lastIndex = currentIndex
}
}
}
//--------------------------------------
// Log compaction
//--------------------------------------
func (s *server) TakeSnapshot() error {
...
// Attach snapshot to pending snapshot and save it to disk.
s.pendingSnapshot.Peers = peers
s.pendingSnapshot.State = state
s.saveSnapshot()
// We keep some log entries after the snapshot.
// We do not want to send the whole snapshot to the slightly slow machines
if lastIndex-s.log.startIndex > NumberOfLogEntriesAfterSnapshot {
compactIndex := lastIndex - NumberOfLogEntriesAfterSnapshot
compactTerm := s.log.getEntry(compactIndex).Term()
s.log.compact(compactIndex, compactTerm) ///compact log entry
}
}
snapshot数据内容
// Snapshot represents an in-memory representation of the current state of the system.
type Snapshot struct {
LastIndex uint64 `json:"lastIndex"`
LastTerm uint64 `json:"lastTerm"`
// Cluster configuration.
Peers []*Peer `json:"peers"`
State []byte `json:"state"`
Path string `json:"path"`
}
// save writes the snapshot to file.
func (ss *Snapshot) save() error {
// Open the file for writing.
file, err := os.OpenFile(ss.Path, os.O_CREATE|os.O_WRONLY, 0600)
if err != nil {
return err
}
defer file.Close()
// Serialize to JSON.
b, err := json.Marshal(ss)
...
log compact
将commit Index之后(包括本身)的log entry写到新的文件,然后通过rename覆盖旧的log file。
//--------------------------------------
// Log compaction
//--------------------------------------
// compact the log before index (including index)
func (l *Log) compact(index uint64, term uint64) error {
var entries []*LogEntry
...
/** 节点可能刚从snapshot恢复,current Index(最新的log entry的index)可能小于commit Index;
这时,不进行compact */
// nothing to compaction(important)
// the index may be greater than the current index if
// we just recovery from on snapshot
if index >= l.internalCurrentIndex() {
entries = make([]*LogEntry, 0)
} else {
// get all log entries after index
entries = l.entries[index-l.startIndex:]
}
// create a new log file and add all the entries
new_file_path := l.path + ".new"
file, err := os.OpenFile(new_file_path, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0600)
if err != nil {
return err
}
for _, entry := range entries {
position, _ := l.file.Seek(0, os.SEEK_CUR)
entry.Position = position
if _, err = entry.Encode(file); err != nil {
file.Close()
os.Remove(new_file_path)
return err
}
}
file.Sync()
old_file := l.file
// rename the new log file
err = os.Rename(new_file_path, l.path)
...
log entry in log file
- 格式
log file中的log entry的格式为: len(8个字节的ascii码) + protobuf.LogEntry:
func (e *LogEntry) Encode(w io.Writer) (int, error) {
b, err := proto.Marshal(e.pb)
if err != nil {
return -1, err
}
///length
if _, err = fmt.Fprintf(w, "%8x\n", len(b)); err != nil {
return -1, err
}
return w.Write(b)
}
type LogEntry struct {
Index *uint64 `protobuf:"varint,1,req" json:"Index,omitempty"`
Term *uint64 `protobuf:"varint,2,req" json:"Term,omitempty"`
CommandName *string `protobuf:"bytes,3,req" json:"CommandName,omitempty"`
Command []byte `protobuf:"bytes,4,opt" json:"Command,omitempty"`
XXX_unrecognized []byte `json:"-"`
}
- 示例
SyncCommand:
type SyncCommand struct {
Time time.Time `json:"time"`
}
// The name of the Sync command in the log
func (c SyncCommand) CommandName() string {
return "etcd:sync"
}
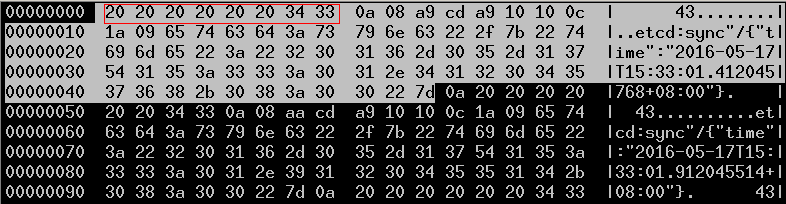
前面8个字节为长度,20为空格,34 33对应0x43,即记录长度为67个字节。后面字节为protobuf.LogEntry。
选举
整体框架:
//--------------------------------------
// Event Loop
//--------------------------------------
// ________
// --|Snapshot| timeout
// | -------- ______
// recover | ^ | |
// snapshot / | |snapshot | |
// higher | | v | recv majority votes
// term | -------- timeout ----------- -----------
// |-> |Follower| ----------> | Candidate |--------------------> | Leader |
// -------- ----------- -----------
// ^ higher term/ | higher term |
// | new leader | |
// |_______________________|____________________________________ |
// The main event loop for the server
func (s *server) loop() {
defer s.debugln("server.loop.end")
state := s.State()
for state != Stopped {
s.debugln("server.loop.run ", state)
switch state {
case Follower:
s.followerLoop()
case Candidate:
s.candidateLoop()
case Leader:
s.leaderLoop()
case Snapshotting:
s.snapshotLoop()
}
state = s.State()
}
}
选举过程
- (1)follower发起vote
如果follower在election timout内没有收到leader的心跳,就会将自己设置为Candidate,并发起选举(Vote)。读取log entry中最新index和term,将自己的Term++,然后将这3个信息封装到RequestVoteRequest,同时发给所有peer;然后计票器置1(votesGranted=1)
// The event loop that is run when the server is in a Candidate state.
func (s *server) candidateLoop() {
...
lastLogIndex, lastLogTerm := s.log.lastInfo()
doVote := true
...
for s.State() == Candidate {
if doVote {
// Increment current term, vote for self.
s.currentTerm++ ///(0)Term加1
s.votedFor = s.name
// Send RequestVote RPCs to all other servers.
respChan = make(chan *RequestVoteResponse, len(s.peers))
for _, peer := range s.peers { ///(2)向其它所有节点发送vote request
s.routineGroup.Add(1)
go func(peer *Peer) {
defer s.routineGroup.Done()
peer.sendVoteRequest(newRequestVoteRequest(s.currentTerm, s.name, lastLogIndex, lastLogTerm), respChan)
}(peer)
}
// Wait for either:
// * Votes received from majority of servers: become leader
// * AppendEntries RPC received from new leader: step down.
// * Election timeout elapses without election resolution: increment term, start new election
// * Discover higher term: step down (§5.1)
votesGranted = 1
timeoutChan = afterBetween(s.ElectionTimeout(), s.ElectionTimeout()*2)
doVote = false
}
///(3)收到多数节点的赞成票,切换成leader
// If we received enough votes then stop waiting for more votes.
// And return from the candidate loop
if votesGranted == s.QuorumSize() {
s.debugln("server.candidate.recv.enough.votes")
s.setState(Leader)
return
}
// Collect votes from peers.
select {
case <-s.stopped:
s.setState(Stopped)
return
case resp := <-respChan:
if success := s.processVoteResponse(resp); success {
s.debugln("server.candidate.vote.granted: ", votesGranted)
votesGranted++ ///(4)receive approval
}
- (2)其它节点投票
其它节点(包括leader和其它follower节点)收到vote request(RequestVoteRequest)后,会比较Term、log.lastIndex、log.lastTerm;如果request中这3个值都大于follower自身的值,就投赞成,否则就反对:
// Processes a "request vote" request.
func (s *server) processRequestVoteRequest(req *RequestVoteRequest) (*RequestVoteResponse, bool) {
...
///(0)比较Term
// If the request is coming from an old term then reject it.
if req.Term < s.Term() {
return newRequestVoteResponse(s.currentTerm, false), false
}
// If the term of the request peer is larger than this node, update the term
// If the term is equal and we've already voted for a different candidate then
// don't vote for this candidate.
if req.Term > s.Term() {
s.updateCurrentTerm(req.Term, "")
} else if s.votedFor != "" && s.votedFor != req.CandidateName {
return newRequestVoteResponse(s.currentTerm, false), false
}
///(1)比较lastIndex、lastTerm
// If the candidate's log is not at least as up-to-date as our last log then don't vote.
lastIndex, lastTerm := s.log.lastInfo()
if lastIndex > req.LastLogIndex || lastTerm > req.LastLogTerm {
return newRequestVoteResponse(s.currentTerm, false), false
}
...
s.votedFor = req.CandidateName ///remember voted node
return newRequestVoteResponse(s.currentTerm, true), true
}
** 问题1: 其它节点在收到vote request时,如果之前已经投票给别的节点,怎么办? **
其它节点在收到RequestVoteRequest时,会先比较Term,如果req.Term > self.currentTerm,节点就会将自己的Term设置为req.Term,不管之前是否收到过其它节点的vote request。
如果req.Term == seflt.currentTerm,就会比较给之前投票的节点与这次请求的节点是否相同,如果不同,意味着已经投票给其它节点,就对这次请求的节点投反对票。
** 问题2: leader频繁切换 **
对于leader节点,如果收到follower的vote request,也会执行上面的投票过程。考虑3个节点:A(leader)、B(follower)、C(follower),且当前三者的Term是相同的。
如果在某个点,由于网络波动原因,B没有在election timoute时间内收到A的心跳,B就会发起选举,这时,A和C都会投赞成票,导致leader从A -> B。也就是说,网络波动等原因很容易引起leader变来变去。这可以通过增加follower的election timeout值来规避。
* v2.x如何解决这个问题?*
- (3) follower -> leader
follower每收到一个赞成票,就对votesGranted加1,如果收到多数节点的赞成票,就将自己提升为leader。至此,选举结果。
如果follower发现其它某个节点的Term比自己的Term大,就会更新自己的Term(也意味着选举失败)。
几个Index
etcd会在Http response header附带下面几个Index信息:
X-Etcd-Index: 35
X-Raft-Index: 5398
X-Raft-Term: 0
- X-Etcd-Index
对应store.CurrentIndex,etcd的每次更新操作都会导致该值加1:
/// implement raft.StateMachine
type store struct {
Root *node ///root node
WatcherHub *watcherHub
CurrentIndex uint64
Stats *Stats
CurrentVersion int
ttlKeyHeap *ttlKeyHeap // need to recovery manually
worldLock sync.RWMutex // stop the world lock
}
func (s *store) internalCreate(nodePath string, dir bool, value string, unique, replace bool,
expireTime time.Time, action string) (*Event, error) {
currIndex, nextIndex := s.CurrentIndex, s.CurrentIndex+1
...
s.CurrentIndex = nextIndex
return e, nil
}
X-Etcd-Index只是etcd使用的一个index,与内部raft server没有关系,即与raft算法没有关系。
- X-Raft-Index
X-Raft-Index是etcd内部raft server的index,即raft算法使用的index。实际上,该值对应log.commitIndex,也就是也就是完成commit的log entry对应的Index。
///etcd server
// The current Raft committed index.
func (s *Server) CommitIndex() uint64 {
return s.peerServer.RaftServer().CommitIndex()
}
///raft server
// Retrieves the current commit index of the server.
func (s *server) CommitIndex() uint64 {
s.log.mutex.RLock()
defer s.log.mutex.RUnlock()
return s.log.commitIndex
}
// A log is a collection of log entries that are persisted to durable storage.
type Log struct {
ApplyFunc func(*LogEntry, Command) (interface{}, error)
file *os.File
path string
entries []*LogEntry
commitIndex uint64 ///commit Index
mutex sync.RWMutex
startIndex uint64 /// the index before the first entry in the Log entries
startTerm uint64
initialized bool
}
当节点commit log entry时,就会更新该值:
// Updates the commit index and writes entries after that index to the stable storage.
func (l *Log) setCommitIndex(index uint64) error {
...
// Find all entries whose index is between the previous index and the current index.
for i := l.commitIndex + 1; i <= index; i++ {
entryIndex := i - 1 - l.startIndex
entry := l.entries[entryIndex]
// Update commit index.
l.commitIndex = entry.Index() ///(0)更新log.commitIndex
// Decode the command.
command, err := newCommand(entry.CommandName(), entry.Command())
if err != nil {
return err
}
// Apply the changes to the state machine and store the error code.
returnValue, err := l.ApplyFunc(entry, command)
...
** log entry index的来源? **
raft server处理一个Command(操作)时,就会创建一条log entry(LogEntry);每创建一个log entry,就意味着log entry index + 1 :
// Processes a command.
func (s *server) processCommand(command Command, e *ev) {
s.debugln("server.command.process")
// Create an entry for the command in the log.
entry, err := s.log.createEntry(s.currentTerm, command, e)
...
func (l *Log) createEntry(term uint64, command Command, e *ev) (*LogEntry, error) {
return newLogEntry(l, e, l.nextIndex(), term, command)
}
// The next index in the log.
func (l *Log) nextIndex() uint64 {
return l.currentIndex() + 1
}
// The current index in the log without locking
func (l *Log) internalCurrentIndex() uint64 {
if len(l.entries) == 0 { ///没有log entry,当节点新创建时
return l.startIndex
}
return l.entries[len(l.entries)-1].Index()
}
- X-Raft-Term
选举向量,当有follower发起选举时,该值就会加1。
- 总结
(1) X-Etcd-Index表示etcd server逻辑上处理了多少个(带自client的)更新请求,比如处理一个Set操作,就会加1。
(2) X-Raft-Index 表示内部raft协议(算法)创建了多个log entry,每创建一个log entry就会加1。注意,并不是只有上层etcd server的更新操作会导致raft协议创建log entry。etcd集群内部节点的加入或者离开也会导致创建log entry。
(3) X-Raft-Term表示集群发生选举的次数,每一次新的选举,就会加1。
(4) 所以,X-Etcd-Index保证etcd数据的逻辑上一致性、X-Raft-Index保证内部raft协议的一致性、X-Raft-Term保证选举的一致性。对于完全一致的集群,在没有更新的时刻,这3个值应该都是相同的。