swap space
关于swap space的介绍,就可以参考All about Linux swap space。
当内存不足时,内核会进行页面回收,此时主要有2个选择:file cache pages和anonymous pages,参考Linux中进程内存与cgroup内存的统计。
对于file cache,内核只需要将page的数据回写到文件后即可。对于anonymous page,内核需要将page的数据写到swap spac,swap space主要就用于存储被换出的modified anonymous pages。
关于swap,有以下几点需要说明:
(1)Swap space does not inherently slow down your system. In fact, not having swap space doesn't
mean you won't swap pages. It merely means that Linux has fewer choices about what RAM can be reused
when a demand hits. Thus, it is possible for the throughput of a system that has no swap space to
be lower than that of a system that has some.
Swap并不意味着会使用系统变慢。实际上,没有swap也并不是意味着系统不会换出page(注:比如file
cache),只是意味着内核在重用page时少了一些选择(注:不能重用modified anonymous pages)。
(2)Swap space is used for modified anonymous pages only. Your programs, shared libraries and
filesystem cache are never written there under any circumstances.
Swap space仅用于被修改的匿名页。
(3)Given items 1 and 2 above, the philosophy of “minimization of swap space” is really just a
concern about wasted disk space.
swappiness
vm.swappiness
内核参数vm.swappiness可以控制内核在回收内存时,对anonymous page 的处理策略(回收匿名页数量的比例)。
anon_prio = vm.swappiness
file_prio = 200 - vm.swappiness
vm.swappiness取值从0~100,默认值会60。此时file_prio=160,内核回收的file cache的比例会大一些。如果vm.swappiness=0,内核回收内存时,就不会回收匿名页,直到系统的free+file cache < high water mark in a zone(注:仅对于全局回收,不包括mem cgroup引起的回收)。
high water mark是根据/proc/sys/vm/min_free_kbytes计算的一个值,参考这里。
memory.swappiness
另外,考虑到mem cgroup,memory.swappiness(默认值为60)会影响group的内存回收。
内核主要有4种LRU链表:
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};
inactive_anon - # anonymous and swap cache memory on inactive LRU list.
active_anon - #anonymous and swap cache memory on active LRU list.
inactive_file - # file-backed memory on inactive LRU list.
active_file - # file-backed memory on active LRU list.
内核回收内存时,会在get_scan_out中计算每个链表中回收的page数量:
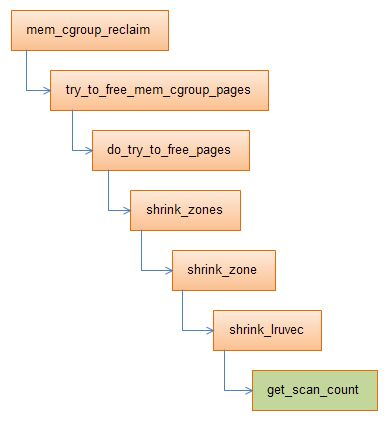
/*
* Determine how aggressively the anon and file LRU lists should be
* scanned. The relative value of each set of LRU lists is determined
* by looking at the fraction of the pages scanned we did rotate back
* onto the active list instead of evict.
*
* nr[0] = anon inactive pages to scan; nr[1] = anon active pages to scan
* nr[2] = file inactive pages to scan; nr[3] = file active pages to scan
*/
static void get_scan_count(struct lruvec *lruvec, struct scan_control *sc,
unsigned long *nr)
** (1)如果没有swap space,就不会回收anonymous page: **
/* If we have no swap space, do not bother scanning anon pages. */
if (!sc->may_swap || (get_nr_swap_pages() <= 0)) {
scan_balance = SCAN_FILE;
goto out;
}
** (2)如果是group回收,且memory.swappiness==0,则回收file cache: **
/*
* Global reclaim will swap to prevent OOM even with no
* swappiness, but memcg users want to use this knob to
* disable swapping for individual groups completely when
* using the memory controller's swap limit feature would be
* too expensive.
*/
if (!global_reclaim(sc) && !vmscan_swappiness(sc)) {
scan_balance = SCAN_FILE; ///mem cgroup swappiness == 0
goto out;
}
** (3)系统(group)内存已经不足,且swappiness!=0,则anon page和file cache都可以回收: **
/*
* Do not apply any pressure balancing cleverness when the
* system is close to OOM, scan both anon and file equally
* (unless the swappiness setting disagrees with swapping).
*/
if (!sc->priority && vmscan_swappiness(sc)) {
scan_balance = SCAN_EQUAL;
goto out;
}
** (4)如果空闲页(free)+file cache小于high water mark,则回收anon page(注:仅对全局回收): **
anon = get_lru_size(lruvec, LRU_ACTIVE_ANON) +
get_lru_size(lruvec, LRU_INACTIVE_ANON);
file = get_lru_size(lruvec, LRU_ACTIVE_FILE) +
get_lru_size(lruvec, LRU_INACTIVE_FILE);
/*
* If it's foreseeable that reclaiming the file cache won't be
* enough to get the zone back into a desirable shape, we have
* to swap. Better start now and leave the - probably heavily
* thrashing - remaining file pages alone.
*/
if (global_reclaim(sc)) {
free = zone_page_state(zone, NR_FREE_PAGES);
if (unlikely(file + free <= high_wmark_pages(zone))) {
scan_balance = SCAN_ANON;
goto out;
}///file cache isn't enough, add ANON
}
** (5)inactive file cache足够,则回收file cache: **
/*
* There is enough inactive page cache, do not reclaim
* anything from the anonymous working set right now.
*/
if (!inactive_file_is_low(lruvec)) {
scan_balance = SCAN_FILE;
goto out;
}
** (6)其它情况,则根据swappiness计算回收anon page和file cache page的数量: **
scan_balance = SCAN_FRACT;
/*
* With swappiness at 100, anonymous and file have the same priority.
* This scanning priority is essentially the inverse of IO cost.
*/
anon_prio = vmscan_swappiness(sc);
file_prio = 200 - anon_prio;
小结
从上面的代码逻辑来看cgroup的memory.swappiness在单个group回收内存时生效,全局的vm.swappiness在全局回收内存时生效。考虑到docker容器,如果需要关闭容器的swap,则需要设置cgroup的memory.swappiness,而与vm.swappiness无关。
测试
关闭hierarchy。
# cat /cgroup/memory/memory.use_hierarchy
0
以memory.swappiness=0启动容器:
# docker run -it --rm -m 1024m --memory-swappiness=0 dbyin/stress --vm 1 --vm-bytes 1536M --vm-hang 0
WARNING: Your kernel does not support swap limit capabilities, memory limited without swap.
stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
stress: FAIL: [1] (415) <-- worker 5 got signal 9
stress: WARN: [1] (417) now reaping child worker processes
stress: FAIL: [1] (421) kill error: No such process
stress: FAIL: [1] (451) failed run completed in 1s
可以看到,容器出现OOM:
Task in /docker/555fa75e9e7d3e552337365e093719a6ec9379ef98907fca8d6f3328054cdb42 killed as a result of limit of /docker/555fa75e9e7d3e552337365e093719a6ec9379ef98907fca8d6f3328054cdb42
memory: usage 1048576kB, limit 1048576kB, failcnt 267
memory+swap: usage 0kB, limit 9007199254740991kB, failcnt 0
kmem: usage 0kB, limit 9007199254740991kB, failcnt 0
Memory cgroup stats for /docker/555fa75e9e7d3e552337365e093719a6ec9379ef98907fca8d6f3328054cdb42: cache:188KB rss:1048388KB rss_huge:1044480KB mapped_file:16KB inactive_anon:588548KB active_anon:459808KB inactive_file:52KB active_file:16KB unevictable:0KB
[ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj name
[ 3893] 0 3893 1655 22 8 0 0 stress
[ 3897] 0 3897 394872 262036 521 0 0 stress
Memory cgroup out of memory: Kill process 3897 (stress) score 1001 or sacrifice child
Killed process 3897 (stress) total-vm:1579488kB, anon-rss:1048132kB, file-rss:12kB
以memory.swappiness!=0启动容器:
# docker run -it --rm -m 1024m dbyin/stress --vm 1 --vm-bytes 1536M --vm-hang 0
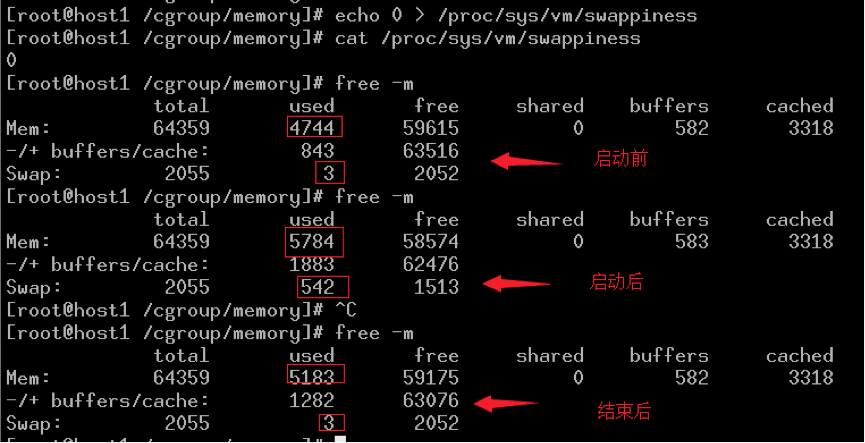
可以看到容器可以正常启动,OS swap发生变化,仅管vm.swappiness=0,对容器并没有影响。
修改memory.swappiness
当修改容器的swappiness时,出现下面的错误:
# echo 0 > memory.swappiness
-bash: echo: write error: Invalid argument
对于3.16以下的内核,有下面的限制:
Following cgroups’ swappiness can’t be changed.
(1)root cgroup (uses /proc/sys/vm/swappiness).
(2)a cgroup which uses hierarchy and it has other cgroup(s) below it.
(3)a cgroup which uses hierarchy and not the root of hierarchy.
static int mem_cgroup_swappiness_write(struct cgroup *cgrp, struct cftype *cft,
u64 val)
{
struct mem_cgroup *memcg = mem_cgroup_from_cont(cgrp);
struct mem_cgroup *parent;
if (val > 100)
return -EINVAL;
if (cgrp->parent == NULL)
return -EINVAL;
parent = mem_cgroup_from_cont(cgrp->parent);
mutex_lock(&memcg_create_mutex);
/* If under hierarchy, only empty-root can set this value */
if ((parent->use_hierarchy) || memcg_has_children(memcg)) {
mutex_unlock(&memcg_create_mutex);
return -EINVAL;
}
memcg->swappiness = val;
mutex_unlock(&memcg_create_mutex);
return 0;
}
3.16以上的内核已经去除了这个限制,参考这里
3.16以下的内核解决的方法就是将memory.use_hierarchy设置为0。
#echo 0 > memory.use_hierarchy
mem cgroup hierarchy
The memory controller supports a deep hierarchy and hierarchical accounting.The hierarchy is created by creating the appropriate cgroups in the cgroup filesystem. Consider for example, the following cgroup filesystem hierarchy
root
/ | \
/ | \
a b c
| \
| \
d e
In the diagram above, with hierarchical accounting enabled, all memory usage of e, is accounted to its ancestors up until the root (i.e, c and root), that has memory.use_hierarchy enabled. If one of the ancestors goes over its limit, the reclaim algorithm reclaims from the tasks in the ancestor and the children of the ancestor.